
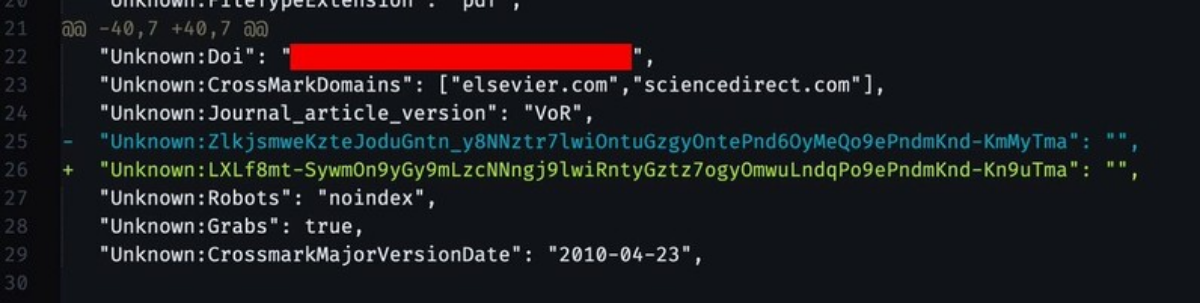
Combined with access timestamps, they can uniquely identify the source of any shared PDFs.
Source: https://social.coop/@jonny/107685726645817029 – Also includes tips for removing this data.
deleted by creator
Back then, when I was still in academia, I actually put every paper I wrote and the corresponding data/code on my academic website for everyone to download. I can’t understand why this isn’t required for every (publicly funded) researcher!
This should be expected. In the future netflix, YT and Spotify will probably do that to their content as well to combat piracy.
I obviously oppose it. But if privacy is of no value to you (like it is to them), it’s the logical thing to do.
I wouldn’t be surprised if some audio watermarking is already going on right now. Universal Music Group has done this for a while on their music. In 2008 UMG was using watermarks unique to each distributor, not to each person purchasing or streaming the watermark. I’m not sure if UMG is still doing this, in the update on the first blog post linked, some said it has stopped, some say it hasn’t.
The technology to do it is already there. I’m not surprised if near-inaudible audio watermarking exists now, I’m not an expert on this field. To put an unique ID per subscriber can be done as well on a technical level I assume. I believe whether this is done depends on the streaming service or download store, because it comes at a cost of using more computing power on their servers. I don´t know whether it is allowed by the GDPR and similar laws either.
I don’t know if it is worth it either. If I look around into my social circle, most people have moved towards streaming services. Only a “stubborn” few, such as myself, still—legally or illegally—download music. Based on this, I feel like music piracy isn’t as big as it used to be.
First of all I’m all in for privacy but in this case they keep your key private. Only YOU can leak your personalized content with your private key. So I don’t see what they would be doing wrong.
the most secure private way to ensure no watermarking: extract the all the information and regenerate the document
Reminds me of the watermarking RedStarOS does to files
What it does?
From memory, RedStarOS keeps a chain of where the file has been so if illegal material is distributed they can easily trace its source and who’s used it
So that is what makimg pdf files so big.
But how is this in !privacy? It’s anti-piracy.
If you download a paper you should know that it has a unique fingerprint. If your cloud gets hacked, and the paper released with your “signature”, it affects you.
Yeah, it should be clearly visible. E-books bought from certain shops come with a notice like “This copy was bought by Tiuku” on the first page (and probably have something like this embedded as well). When it’s done in the open like this, I think it’s a pretty fair way of doing DRM.
Is it ‚really‘ fair, though?
When I buy a physical book, I can borrow it to others or resell it as I please without ever really having to reveal Information about myself. Why must a digital copy of the same book be forever branded with my name/account info?






{kind=link}