

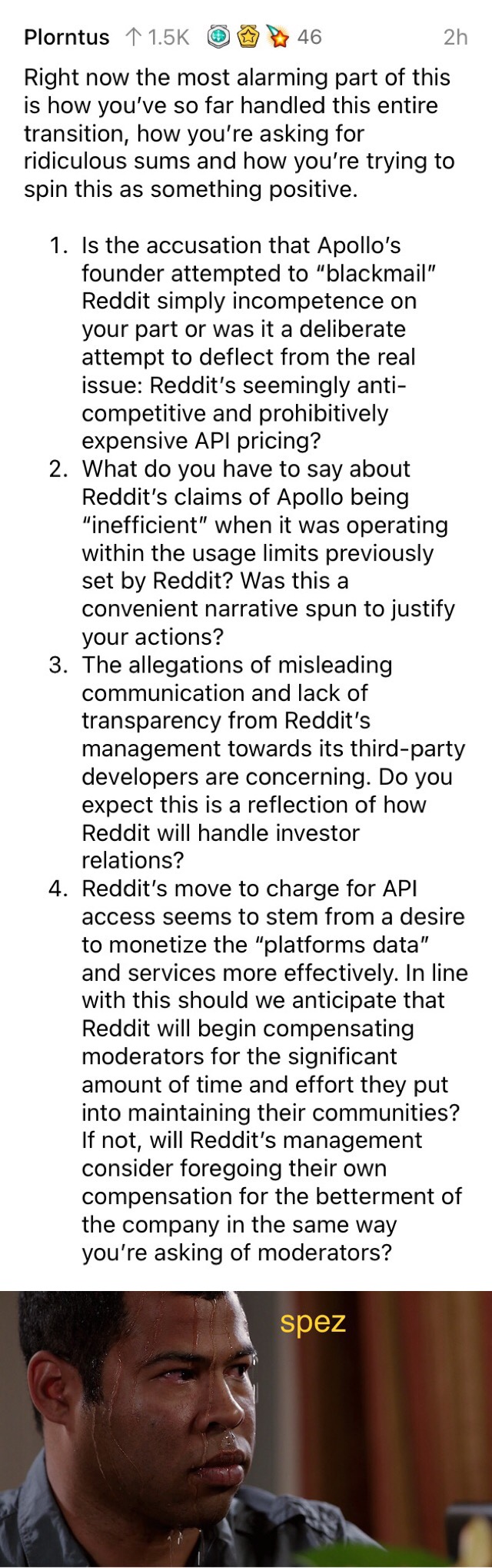
Do you expect this is a reflection of how Reddit will handle relations with its investors?
Holy shit, they killed him right there. They have put the thread in “sort by new” mode and I bet it’s just to bury that bomb as deep as they can.
Apollo didn’t auto switch it for me so it was at the top lol. Of course Spez ignored that one. He actually took a shot at Christian in another comment
Saw that. Glad lemmy is taking off.
Same. I just started today and I’m having fun with it. Feels like when I just started Reddit. Definitely not as many communities but I feel like it’ll get there.
Yeah it will. Even it doesn’t reach critical mass if it just becomes a tight nit community on here I’m fine with that.
I think Reddit was just to big anyway, i think we are just early for the big wave when the changes over there are through.
the nice thing with federation is that you can always find a smaller community on a smaller instance if thats what you want while still having access to the larger ones. its… magical! :-)
I hopped onto Lemmy yesterday when I saw the news that Sync was shutting down. Already enjoying the communites more than I ever was on reddit.
Is Lemmy the biggest contender for a Reddit alternative rn?
It’s the only one I’ve heard of so I’d assume so but I’m also curious to know the answer to your question too.
It’s definitely one of the ones with the most promise. I say “one of the ones” because there’s also kbin and it literally doesn’t matter which one you use, you get the same content. Any new fediverse reddit-like that pops up is also swimming in the same stream, can only compete on features and administration, not on content lock-in. The fediverse is pretty dope.
My favourite part is when Christian
deleted by creator
deleted by creator
The absolute destruction of the man. And to make things even worse he continued to dig in the Apollo dev. Unbelievable!
Sort by new mode? I guess I haven’t heard of that… on account of using a 3rd party app for years.
Why the fuck did they even remotely think this would be a good idea anyway? There is literally 0 good will towards reddit right now and for good reason.
I’m on Lemmy now, so actually it was a brilliant idea
I just checked and my account on lemmy is 3 years old, I was waiting for all of you. At moments lemmy looked like it will take of by it self, but last few months was pretty quiet. I hope this is the push this community needs to succeed.
Reddit got too big for my taste since digg joined in, I don’t think this will kill it ( they have the data how many people is using it outiside official apps), but let’s make space out of it.
We just need a easy to use, beautiful mobile client and so many people will switch over to it.
Jerboa is pretty good tbh.
Yeah I’m impressed actually. Absolutely a big improvement over the web browser on the phone.
I’m using jerboa currently. Albeit very new to the app, but I’m still a bit put off by the lack of options for personization and features. It also desperately needs an in app browser so all the links stop sending me out of the app.
There is definitely potential here, but leaves a lot to be desired.
Yeah, honestly it isn’t too bad. I was a little put-off by the size of everything at first, but, when I checked the settings, there is an option to change the size of the font—and that really helped.
All in all, it isn’t perfect, but I am enjoying it so far. I look forward to seeing it grow and improve!
One can only dream that these canceled 3rd party clients might join some day. Hopefully some will be opensource or they decide to support any other platform.
It would’ve been great if they just collectively change to something else.
The Tafkars API might be helpful in that: Tafkars: Reddit-API proxy for Lemmy (help wanted). To quote,
- I’ve been working on a proxy that makes it possible for 3rd party Reddit apps to connect to Lemmy with minimal code changes. Ideally all that’s needed is to swap out the url for that of the proxy. Naturally it’s open source.
That’s great! Thanks for the info
the dev for RedReader (minimalist and awesome FLOSS reddit client) has indicated RR will be targeting Lemmy as soon as Lemmy instances smooth out after an anticipated load ramp up from reddit defectors. I am sure others are planning the same thing.
Absolutely great news. RedReader was my go-to app for a while now. The absolute dedication to function over form is/was praise-worthy.
This is what I am really waiting for, to be honest. Jerboa is too slow and jerky for my liking.
Probably not just waiting for instances to smooth out, but waiting to see if reddit actually follows through. I think they likely will, but there is an off chance heads roll when they realize all the people creating, aggregating, and moderating their site are the ones that are pissed off and leaving. The casuals may not care directly about this decision, but they will when the content goes to shit.
Dude Apollo for lemmy would be game changing. Let’s get the dev on board!
While I agree that porting one of these great reddit clients to a new platform like Lemmy is the way to go, I don’t see why it should be done by the individual developer instead of treated as a community effort. We’ll just end up in the same boat again where he’s piggy backing on another project (Lemmy, etc) to build a closed-source business that only he profits from. And while I have no problem with people selling apps they wrote, if none of these developers are going to open source their work so that the community can participate, I’d rather see a longer term effort go into improving FOSS solutions.
All it took was for a few power users, aka content thieves, someone like MrBabyMan who’s spent all their conscious energy and time submitting entertaining content from other less user friendly platforms, to convince a majority of users on the internet to pay attention to reddit more.
Simply getting more content, regardless of its quality or dubious origin, only as long as it is interesting or entertaining, will draw more users here. This is probably not what people want, but that’s what it will take for Lemmy to take off.
deleted by creator
Those memes look organic and sustainably sourced, delightful!
deleted by creator
You’re right, that’s absolutely what I don’t want
If one was still browsing reddit using rif and seldomly old reddit it somehow still felt similar to what it was 10 or more years ago. Over time I ditched Facebook and some other social media I used but Reddit somehow stayed. Maybe because it was the “anonymous” one, the one I just used for myself without sharing my account with my real-life friends.
Anyway thanks for waiting for us, took some time for me to get up and leave reddit. I hope others will follow, but so far even for me as a software dev/ architect it was quite a change to switch to fediverse services. Maybe it’ll be smoother when you’re joining bigger servers but let’s see what the future brings. As a fan of Foss I’d really like to see this thing grow.
Agree, Reddit itself is unusable without old design.
It’s the IPO. This has been the plan since day one (or at least since Conde Nast). Reddit hasn’t been operating at a loss for almost twenty years out of the goodness of their heart. It doesn’t matter how much the users hate it, the users are what is for sale.
deleted by creator
deleted by creator
@lemmy_steve @AineLasagna it’s such an obvious cash grab and not at all fair to the communities or moderators that provide content and manage communities for FREE. Sad to see it go.
Also not sure how to go about making my mastodon feed closer to Reddit but that’s at least my first plan
try Kbin!
deleted by creator
I feel like this move has nothing to do with investors and everything to do with setting the standard for big corps like Microsoft and Google to be able to scrape their massive amount of data to train next gen AIs. They know they have HUGE amount of data from now and for years and years ago. Content, created by others, then sold for enormous profit.
I mean AI is already stealing all art and images on the web without paying anything. They could just literally scrape and pay nothing. Web scraping isn’t illegal, they already do it, why would they pay anyone? Unless the law catches up about the rights to manufacture AI content based on ill-gotten data, then why would they pay what they don’t have to?
deleted by creator
Could you please point me to legal definitions, in court or otherwise, that say it is not violating my copyright license to directly use my artwork in any shape or form for a non-fair use product? As in, a service you pay money for to create things based on the training data it has taken from me, is not fair use. Or point me to the legal definitions where I lose my copyright by posting things online? Allowing to scrape is not the same thing as giving derivative copyright license permissions. You aren’t disagreeing with me, you’re disagreeing with my legal rights.
deleted by creator
hmm. That talks of data mining not of derivative work from the mined data. … I’ll leave the discussion to others, though.
What effect would a Creative Commons “ND” clause have? Is it reserving the right to make derivatives? And would machine generated stuff even count as a derivative?DuckDuckGo translate:
Copyright and Related Rights Act (Copyright Act) § 44b Text and Data Mining
(1) Text and data mining is the automated analysis of one or more digital or digitized works in order to obtain information, in particular about patterns, trends and correlations.
(2) Reproduction of lawfully accessible works for text and data mining is permitted. The reproductions must be deleted when they are no longer required for text and data mining.
(3) Uses pursuant to subsection (2) sentence 1 shall only be permitted if the rights holder has not reserved them. A reservation of use for works accessible online is only effective if it is made in machine-readable form.deleted by creator
Where has that been proven legally?
Translation: (1) Text and data mining is the automated analysis of one or more digital or digitized works in order to obtain information, in particular about patterns, trends and correlations.
(2) Reproduction of lawfully accessible works for text and data mining is permitted. The reproductions must be deleted when they are no longer required for text and data mining.
(3) Uses pursuant to subsection (2) sentence 1 shall only be permitted if the rights holder has not reserved them. A reservation of use for works accessible online is only effective if it is made in machine-readable form.
None of that says anything about creating profitable derivative work. In fact is specifies patterns, trends and correlations, which does not lead me to believe it is protecting visual works created from this data, those kind of things are only used to inform things, like information science.
deleted by creator
Where are algorithms considered as being new and legally allowed derivative works in relation to visual works of art?
What do you mean by stealing? The data remains, all they do is learning from something which is public
What is different to Googles approach, they are just watching and learning Why is it treated so differently when it essentially does nothing new, but uses the data in a different way
they are just watching and learning Why is it treated so differently
Because it isn’t human. It isn’t watching and learning, it is being fed my creative content as data that I have not allowed nor have been compensated for, which is then turned around and sold as a service. My work is being consumed for commercial uses by an inhuman who does not have fair use education rights, with the sole intent to create a profitable product, and I’m getting nothing. I have legal rights, no matter where I post my work, to retain my copyrights and I have the right to not consent to improper use of my works that do not align with the licenses I have chosen to give it. Websites ask for a licenses in their ToS to be able to even just display and share my artwork when I upload it. When I create an image, I am given ownership of it’s copyright to control the use, distribution, and right to create derivatives. This isn’t a fuzzy area, it’s very clear. If an artist did not consent to their artwork being used as training data for a non-fair use reason, it is stealing their works.
And no, it’s not fair use under education. Copyright exists for human protection and uses. It isn’t being used for ‘learning’ it’s used as data to be repackaged and sold. Google’s use of it showing up in search is to link back to posts that contain my work, retain my copyright, and are not derivatives. If you mean by captchas, yeah capchas are pretty bullshit.
And circling back to my original post. So? AI companies aren’t paying for their image training data, so why would they pay for reddit’s api?
I feel the bigger problem with these AIs is more how they are solely being used to improve profits and productivity, these only affect the capital owners. None of that is going to improve the laborer (i.e., the artist, the coder, the writer, the people who create value from capital). This is only going to get worse. We are being normalized to automation and AI with the use of self-checkout.
Also, about Reddit training data, I think they are too late to the party. The weights they were needed for are made. I do not think they are the exclusive source of specialized information, and (I hope) they are going to find out. They are just going to further show how silly the free market and the stock market are. The people who require the data will probably have other ways of getting it. r/datahoarders and people like that come to mind. Reddit is only making new data hard to access which, which they are not (and hopefully never) an exclusive source of.
Yeah, AI can totally exist and be useful, but currently it’s in the hands of tech dudes and admins who have a terrible track record with developing things responsibly and over hyping and masking flaws. It’s used to make a profit at the colossal detriment to humans. It’s used to hurt us currently, not help at all.
I think the training data from reddit probably only used the API because it was easier and free. And if no longer free, there’s nothing pointing to them actually paying for it. It’s not like reddit is the only data, they very much likely already have web scrapers for other uses that they can just tune for reddit.
Yeah, some people just know how to ruin a cool, nice toy.
True, I can see determined groups finding free/cheaper workarounds for it. They fucked up making it stupid expensive dint they? They could have actually gotten money some money if they were smart about it. oh well cant fix greed.
deleted by creator
The thing I worry about whenever someone mentions this angle: What about Lemmy content? As the community moves away from the commercial platforms in favor of Lemmy, Bluesky, Mastodon etc. Then does that lower the legal barrier for AI companies to train on all this content for free? Is that shift in the legal vulnerability of public content something that users consider? Is that desirable to most users? Are people thinking about that?
Open source and federation mean open source and federation, I don’t see why it shouldn’t be free and legal to scrape for Lemmy and Mastadon. However maybe the servers could issue rate limits and suspicious block lists so they don’t go down due to scrapes.
What I don’t understand is why Reddit didn’t institute the following: All api requests are free up to 100,000 per month per user token. Also in our terms of service you can not use us to train AI models without paying this fee.
I’m with you on that. AI is the future. Just because xxx big corp is doing AI training for their closed source product doesnt mean that open source models won’t also benefit. If you post to a public space you should expect it to be read.
That’s an interesting but definitely plausible take on the whole thing. 12000$ for 50mio requests is B2B pricing. For a company like Openai/Microsoft that’s not even worth thinking about if you get all of that precious training data for it…
If he thinks locking down the API is going to stop them, he’s bumped his head. These companies have more than enough manpower to write and maintain an HTML scraper for Reddit.
Man, even I can do that and I’m hardly a programmer.
That opens them up to massive legal problems if they do. AI companies are going to need to prove their training data was legit obtained.
Creating a web scraper vs actually maintaining one that is effective and works is two different things. It’s very easy to fight web scraping if you know what you are doing.
Right, but these are big companies with lots of talented programmers on hand. If anyone can overcome such an obstacle, it’s them.
Also, Google and Microsoft already have a search index full of Reddit content to scrape.
You are right. You would need a team of skilled scrapers and network engineers though would know how to get around rate limiters with some kind of external load balancer or something along those lines.
Rate limiters work on IP source. This is easily bypassed with a rotating proxy. There are even SaaS that offer this. The trick is to not use large subnets that can be easily blocked. You have to use a lot of random /32 IPs to be effective.
That problem is already solved. Google and Microsoft are already fetching every single page on Reddit for search engine indexing.
Could they be doing that already because of the still open API of Reddit and that will soon change? I just feel like it’s easier for them currently and it will be tougher once the API changes are implemented.
No. Search engines fetch pages using plain old HTTP
GETrequests, same as how browsers fetch pages. There is some difficulty in parsing the HTML and extracting meaningful content, but it’s too late: the HTML is already stored on Google/Microsoft servers, ready for extraction, and there’s nothing Reddit can do to stop them.Reddit can make future content harder to extract, but not without also making it invisible to search engines, which would cause Reddit to disappear from Google Search and Bing.
That’s why I say trying to charge money for AI training data is a fool’s errand. These facts make it impossible. That doesn’t mean Spez won’t try, but it does mean he won’t succeed.
If big tech trains AI using reddit interactions, out species is doomed 🤣
Interesting. I wonder if they already got an offer that matches their new API pricing, and they decided to up everything to match that cost and avoid being sued later.
Like, there seems to be some urgency between them announcing and upping the price. What was it? Is this the reason? A confirmed, extremely wealthy and extremly naive buyer?
The API pricing likely has something to do with the revenue per user calculations. Reddit is aiming for IPO but their valuation tanked over the past two years. That might be why the admins have decided to strong arm this with such a short notice.
deleted by creator
While I appreciate Spez being burned at the stake, why are there so many fucking awards on things. People know that those directly contribute to Reddits revenue right?
I hope most of them are those random free awards Reddit gives out sometimes
If there is a god then maybe.
unfortunately I think we’re pretty certain that god is dead and we killed him so…
deleted by creator
Youre probably right. Man how cringe is that, the idea that Reddit staff is giving themselves rewards.
I’m sure there are some people purchasing those, but you also get some for free. Looks like I have 800 worth I could give out.
Fair enough I suppose. I havent looked into awards in a minute, I assumed they’d gotten rid of all the free ones?
Sometimes you get coin gifts if your posts go viral but yes the free awards have been gone for more than a year at this point. Its possible that many users have them saved up from the past.
They also gave plenty of awards or coins away couple of years ago, just for installing the 1st party client and logging in.
I do like to think people aren’t buying these as of now and just emptying them
The enshittification of Reddit has been evident ever since the new design rolled out. Unusable on mobile devices. Does less, using more memory and bandwidth.
When “New” Reddit came out, it was just shockingly bad. If they didn’t keep old.reddit.com online, they would have killed the site then. Until very recently I couldn’t even view all child comments within the main thread, and it still takes at least twice as long to load any page.
Coming to Lemmy has been a breath of fresh air. The site is much more responsive than Reddit despite most instances running on a single VPS or something.
That’s because the Lemmy webapp focuses on being lean and functional rather than shoving as much telemetry and megabytes of JavaScript bloat as they can to do LESS than the old Reddit webapp could while using 10-20 times MORE resources.
New Reddit is not completely unusable on an intermittent, crammed full 3G connection where Old Reddit just works, but is known to be actively user hostile and somehow cramming full a huge 1080p phone display with only 2 or 3 comments and having to preload for hours for a full thread.
Lemmy server is also blazing fast and being written in Rust which encourages memory safety does help it function better on smaller instances and serve both local and federated clients faster despite having less resources to do so. I really really hope this replaces Reddit in the mainstream and people learn basic concepts about federated media to future proof the free Internet.
It has been a real breath of fresh air and so far it seems more sustainable to spread the bandwidth between smaller instances than let a megacorp fund the infrastructure to serve everyone in a walled garden which will later be enshittified into garbage once a critical mass is already lured in.
EDIT: look for yourself and notice the difference on Firefox’s dev console network tab
You’re right! The front page of Reddit is nearly 8x larger than Lemmy.ml, and took almost 7x longer to load than Lemmy.
Uncached loading results:
Lemmy: 3.3 MB, 39 requests in 1.85 seconds
Old Reddit: 6.3 MB, 60 requests in 4.53 seconds
New Reddit: 24.5 MB, 351 requests in 12.21 seconds
When the new Digg came out, I switched to reddit, now it looks like i found a new place.
The first issue I noticed with new reddit was the missing sidebar. Is that functionality that I should have easily found or is it still missing after all this time?
I was actually shocked when I’ve discovered how much data Reddit app uses compared to RiF for example.
Spez: “This is an askmeanything, not an answeranything.” sits in the corner eating popcorn the whole time
Spez:

deleted by creator
There was even a comment from spez that contained an "A: " at the beginning, proving that those answers are just copy-pasted. lmao
Meanwhile, the sound of microwaves and popcorn ring through the halls of Google HQ.
I thought it was AskMeAnythingAboutRampart
I’ve been following that non AMA for a few hours, and it’s been a bloodbath. Spez really needed to hire a PR team because that was a clown show of epic proportions.
He was caught copy/pasting the softball answers he’d been giving too! He accidentally copied the “A:” in front of one. 😂
General failure answering question A:
Abort, retry, ignore?😂
😂☠️
Reddit, it’s time for an immediate restructuring and damage control. But it’s probably too late.
Always has been
Burn it to the ground! I wish all top subreddits had the balls to go dark indefinitely to the point they have to backpedal or forcibly take over the subreddits. Burn it to the fucking ground!
r/ProgrammerHumor going permanently dark was a watershed moment for me
I don’t think any subs will stay permanently dark, their mods will be replaced eventually.
found a script that deletes all your posts and comments after scrambling them fuck spez and reddit at this point
I want a script that edits all my posts and comments to “Fuck /u/Spez”
Powerdeletesuite can do that. You get to choose what to overwrite all your comments with
Did you find one?
Power delete suite?
I’m surprised they didn’t replace /u/spez with woman; then have her make this announcement. Then he could triumphantly return and claim they will do better from now on. … you know, like the last time they made unpopular changes.
yep, I had a similar train of thought
[spez] screwed up so bad, and it’s obvious he’s quite stupid…I’m wondering if he was given the Ellen Poa treatment. The investor’s knew what changes they wanted to implement to increase revenue, had him implement it, then made him take all the flak. Next, they’ll replace spez with someone else, seemingly roll back a few of the changes, and say they’re working with the reddit community. The thing is that it’s obvious that reddit is irreparably infected. The diseases cannot be eradicated because the disease is corporate greed. Reddit began its time in hospice the moment they shared they were going public. It’s over. Done. Say you final goodbyes. RIP in pieces.
“First, thank you for all the years of dedication to Reddit. You’re amazing.”
“PS I’d like a raise… Oh wait, no I wouldn’t… Because you are not, I repeat, not my boss!”
He ain’t got the balls to answer that.
deleted by creator
































{kind=link}