

Between Lemmy versions v0.8.10 and v0.9.0, we did a major database rewrite, which helped to improve compilation time by around 30% (see below). In this post we are going to explain which methods were effective to speed up Rust compilation for Lemmy, and which werent.
Compilation time comparison
Here is a comparison of debug compilation times for Lemmy. All measurements were done in with Rust 1.47.0, on Manjaro Linux and an AMD Ryzen 5 2600 (6 cores, 12 threads). Results are taken as the average of 5 runs each.
| v0.8.10 | v0.9.0-rc.11 | improvement | |
|---|---|---|---|
| Clean build | 195s | 129s | 34% |
| Incremental build | 23s | 17s | 26% |
Build Graph
The build graph and statistics can be generated with the following command, which will generate a file cargo-timing.html.
cargo +nightly build -Ztimings
In our experience, it is really the most useful tool in order to speed up compilation time. There are a few ways to use it:
- The table at the bottom shows which crates took longest to compile. You can try disable unused features for slow crates, or remove those dependencies entirely. If your own crates are slow, split them up (see below).
- In the bar graph near the top, you can mouse over each crate to see which other crate it has to wait for in order to start compilation. You can try to remove these dependencies, or features that you don’t need.
Splitting code into workspaces
This is often tricky to do, but proved to be the most effective way to speed up compilation. At the same time, it helped to better organise our code into independent parts, which will make future maintenance work easier.
As a first step, it is enough to split the code into crates which depend on each other linearly, as this is relatively easy and already helps to speed up incremental builds (because only part of the project needs to be recompiled when something is changed).
In case you have a particular dependency which takes very long to build, you should take all code which does not depend on that dependency, and move it into a separate crate. Then both of them can be built in parallel, reducing the overall build time.
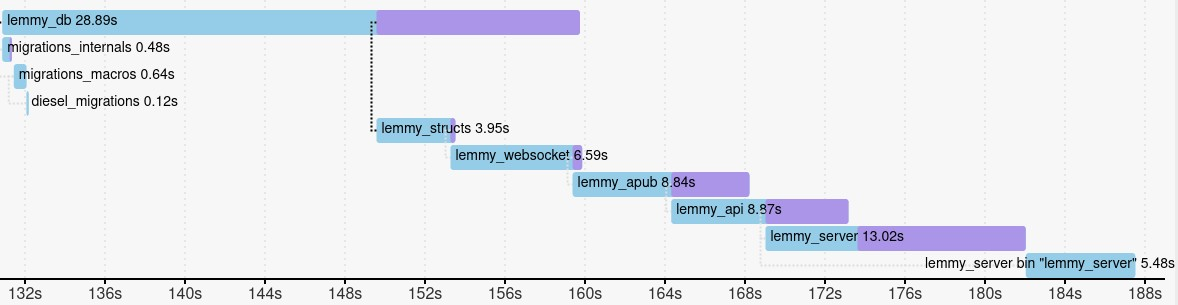
Later you can try to reorganise your code so that crates in your project can be compiled in parallel. You can see below how we did that in Lemmy:
Before:
After:
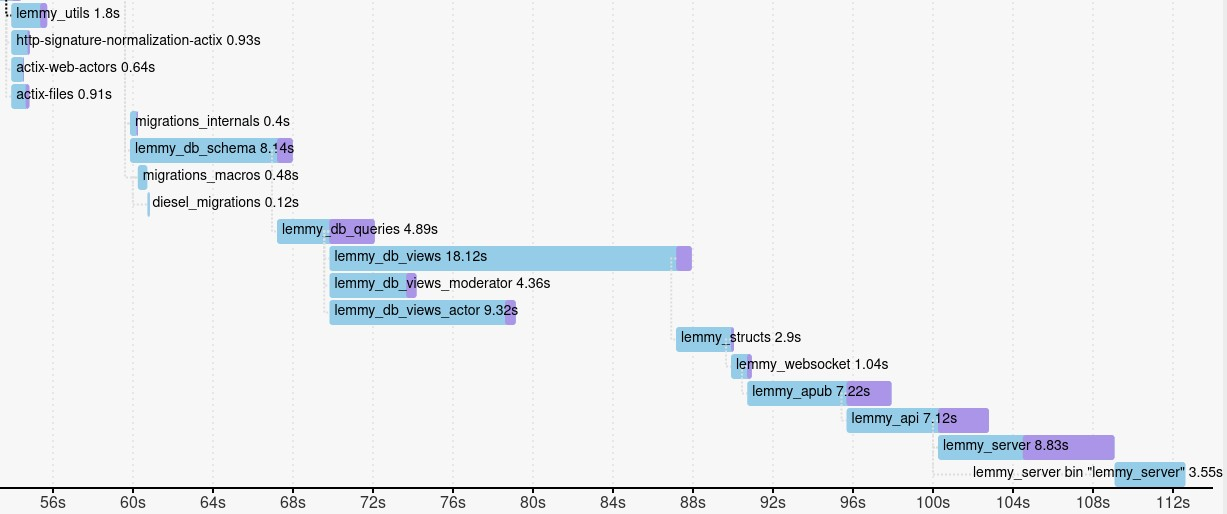
As you can see in the before screenshot, all Lemmy crates are compiled linearly, which takes longer. In the after screenshot, at least some of the database crates are compiled in parallel, which saves time on any computer with multiple CPU cores.
For more details on how to use cargo workspaces, have a look at the documentation
Disabling debug info
This is very easy to do, as it only requires putting the following into Cargo.toml:
[profile.dev]
debug = 0
The effect is that debug information isn’t included in the binary, which makes the binary much smaller and thus speeds up the build (especially incremental builds). We never use a debugger in our development, so changing this doesn’t have any negative effect at all for us. Note that stack traces for crashes still work fine without debug info.
Here it is in the documentation
Removing dependencies
This only had limited success, for the most part. We weren’t willing to remove or replace any of our dependencies, because then we would have to remove features, or have a lot of extra work to reimplement things ourselves.
However, there is one specific dependency where we could improve compilation time by around 50 seconds. Refactoring the database allowed us to remove diesel’s 64-colum-tables feature. This was especially effective because diesel only has a single crate, and as a result is compiled on a single thread. This resulted in a period of 40 seconds where one thread would compile diesel, while all other threads were idle. There is still room for improvement here, if diesel can be split into multiple, parallel crates.
With actix we noticed that it includes a compression library by default, which is useless in our case because we use a reverse proxy. Thanks to @robjtede from the actix for making the necessary changes to allow removing that library. In the end the effect was limited however, because the library could be built very early and in parallel to other things, without blocking anything. It should help with compilation on devices with few CPU cores at least.
Other optimisations
cargo bloat was commonly recommended in order to find large functions, and split them up. But that didn’t help at all in our case, probably because our project is quite large. It might be more useful for smaller projects with less code and less dependencies.
It was also suggested to reduce macro usage, but there wasn’t much opportunity in our case because diesel uses a lot of macros. We removed a few derive statements that weren’t needed, but without any noticable effect.
Thanks for bringing up -Ztimings! Super useful
Good tip on debug=0, I wasn’t aware that stack traces would still work with those disabled.
Awesome! I’ve been following with interest the work on speeding up the compiler itself e.g. https://blog.mozilla.org/nnethercote/2020/04/24/how-to-speed-up-the-rust-compiler-in-2020/
Yes thats great, but unfortunately we are still stuck on Rust 1.47, because one of our dependencies crashes on newer versions.
