

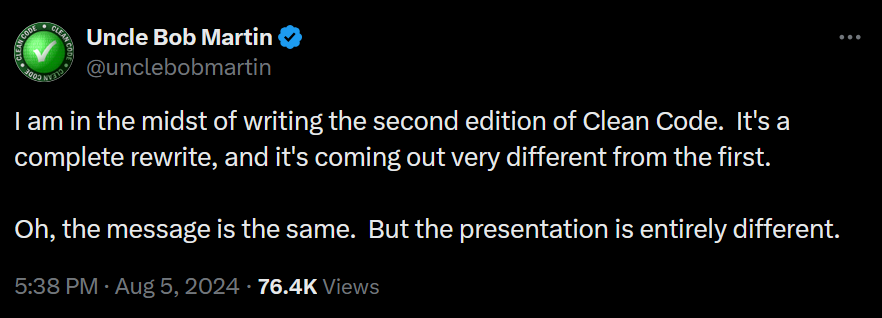
The real joke here is that after causing millions of pointless refactorings and rewrites, now finally the source book is affected as well.
grug even have whole section just for refactor code
inexperienced big brain developer see nested loop and often say “O(n^2)? Not on my watch!”
complexity demon spirit smile
This hits too close to home.
New code is O(n log n), but the time benefits only kicks in when n is above 1 trillion. Otherwise it’s much slower.
And 90% of the time, n is about 3
and 99.9% of the time it is less than 10
I feel like this is a perfect encapsulation of how an experienced self-aware developer thinks. Experience really beats the hard stances out of you. I find myself saying “it depends” and “a bit of column A, bit of column B” often, like a cheap kids toy
Programming is the gradual collection of mantras.
Finally, a development philosophy that sounds unambiguously correct.
But is he rewriting in Rust?
Unlikely, unless his view has changed substantially in the last seven years: https://blog.cleancoder.com/uncle-bob/2017/01/11/TheDarkPath.html
I think his views on how to achieve good quality software are nearly antithetical to the goals of Rust. As expressed in that blog post and in Clean Code, he thinks better discipline, particularly through writing lots and lots of explicit unit tests, is the only path to reliable software. Rust, on the other hand, is very much designed to make the compiler and other tooling bear as much of the burden of correctness as possible.
(To be clear, I realize you’re kidding. But I do think it’s important to know just how at odds the TDD philosophy is from the “safe languages” philosophy.)
Ahhhh, the ol’ “dynamic languages are better than static languages because I have tests that check for different types” argument.
For example, in Swift, if you declare a function to throw an exception, then by God every call to that function, all the way up the stack, must be adorned with a do-try block, or a try!, or a try?
I agree with him on this point. Sounds similar to how it’s in Java, and I hate it. I always wrap my exceptions in a RuntimeExceptions because of this.
I disagree with him the rest of the post. The job of the programmer is to communicate the intent of the program. Both for others and for yourself. The language provides the tools to do so. If a value is intended to be nullable, then I would like to communicate this intent. I think it’s good when a language provides this tool.
Tests don’t communicate the intent of the code. Tests can’t perfectly validate all the possible edge cases of the system either.
Checked exceptions are powerful but misunderstood. Exception types are a useful part of the facade to a module - they express to a caller how it can go wrong even if used correctly.
Runtime exceptions are typically there to express contract-breaking by callers; although as an alternative return mechanism I’ve seen them used to simplify the inner workings of some frameworks.
I think they get a bad rep because there aren’t a ton of good examples of how to use them - even the java classpath had some egregious misuse initially that helped turn people off the key ideas.
Imo, if a method require the caller to do error handling, then that should be part of the return value. For example, use optional or either. Exceptions shouldn’t be part of any expected control flow (like file not found). Exceptions is an emergency panic button.
The problem is that most languages with exceptions treat that as the idiomatic error mechanism. So checked exceptions were invented, essentially, to do exactly what you say: add the exception type to the function signature.
Having separate errors-as-return-values and unwinding-for-emergencies is a much more recent trend (and, IMO, an obviously good development).
I’m not sure why it’s “obviously” good to move from one mechanism to two: as a user I now have to categorise every path to work out which is appropriate.
What I said was less about adding to a function signature than it was about adding to a facade - that is, a system boundary, although the implementation may be the same depending on language. People typically use exceptions pretty badly - a function signature with a baggage-train of internal exceptions that might be thrown by implementation guts is another antipattern that gives the approach a bad rep. Errors have types too (or they should have), and the typical exception constructor has a wrapper capability for good reason.
I should have stressed the “opinion” part of “IMO”. What I mean is that, when I read this, it struck me immediately as being exactly correct: https://joeduffyblog.com/2016/02/07/the-error-model/
That’s fine, and for that there are sum types. My own opinion differs - it’s a question of taste. Being able to bundle the handling of exceptional situations aside from the straight-line logic (or use RAIi-style cleanup) is notationally convenient.
Yes, you can do the same with monads; use the tools available to you.
The exception is part of the method signature and thus part of the return value. I don’t see a difference between using if or try-catch to validate a method call.
I think try catch often leads to messy code. It breaks the control flow in weird ways. For some reason we’ve collectively agreed on that goto is a bad idea, but we’re still using exceptions for error handling.
Consider this example:
try { File file = openFile(); String contents = file.read(); file.close(); return contents: } catch (IoException) { }Say an exception is triggered. Which of these lines triggered the exception? It’s hard to tell.
We might want to handle each type of error differently. If we fail to open the file, we might want to use a backup file instead. If we fail to read the file, we might want to close it and retry with the same file again to see if it works better this time. If we fail to close the file, we might just want to raise a warning. We already got what we wanted.
One way to handle this is to wrap each line around a separate try catch. This is incredibly messy and leads to problematic scopes. Another way is to have 3 different exception types: FileOpenException, FileReadException and FileCloseException. This is also incredibly messy.
Or we can include the error in the return value. Then we can do whatever we want programmatically like any other code we write.
How is that different than what Go, for example, does? An if err != nil after each statement is just as annoying. In the end you have to validate almost all return values and the way it happens is just syntax.
This is an absolute terrible post :/ I cannot believe he thinks that is a good argument at all. It basically boils down to:
Here is a new feature modern languages are starting to adopt.
You might thing that is a good thing. Lists various reasonable reasons it might be a good thing.
The question is: Whose job is it to manage that risk? Is it the language’s job? Or is it the programmer’s job?
And then moves on to the next thing in the same pattern. He lists loads of reasonable reasons you might want the feature gives no reasons you would not want it and but says everything in a way to lead you into thinking you are wrong to think you want these new features while his only true arguments are why you do want them…
It makes no sense.
Yeesh, I thought you were being hyperbolic, but it really is that bad! He even has this massive self report towards the end:
And how do you avoid being punished? There are two ways. One that works; and one that doesn’t. The one that doesn’t work is to design everything up front before coding. The one that does avoid the punishment is to override all the safeties.
And so you will declare all your classes and all your functions open. You will never use exceptions. And you will get used to using lots and lots of ! characters to override the null checks and allow NPEs to rampage through your systems.
Uncle Bob must be the kind of guy who makes all of his types
anywhen writing Typescript.
His take strangely acknowledges that defects are caused by programmers, yet doesn’t want to improve the tools we use to help us not make these mistakes. In summary, git gud.
Experience has taught me that I’m awfully good at finding and firing foot guns, and when I use a language that has fewer foot guns along with good linting, I write reliable code because I tend to focus on what I want the code to do, not how to get there.
Declarative functional programming suits me down to the ground. OOP has been friendly to me, mostly, but it also has been the hardest to understand when I come back to it. Experience has given me an almost irrational aversion to side effects, and my simple mind considers class members as side effects
To my knowledge, the Rust’s book actually encourages writing as many automated tests as you can, as the compiler can’t catch every type of bug in existance.
Yes. True. But Uncle Bob literally complains about non-nullable types in the linked blog post.
I’m not saying testing isn’t important. I’m saying that hand-written unit tests are not the end-all be-all of software quality, and that Uncle Bob explicitly believes they are.
rather strongly typed Java.
[In Java] you can also violate many of the type rules whenever you want or need to
Okay. Well maybe being able to not spell out types every single time would also count as not burdening the programmer ¯\_(ツ)_/¯
I bought Clean Code when I started learning programming, some of it was useful, but now I understand that it was too opinionated for a beginner
Edit: also
Whose job is it to manage that risk? Is it the language’s job? Or is it the programmer’s job[?]
It is language’s job to enforce risk management wherever possible, humans are demonstrated time and time again to be poor at risk management (same for the other questions like ‘whose job it is to check for
nulls’Edit2:
Defects are the fault of programmers. It is programmers who create defects
… and that is why he proposes to not help programmers with language means. I never thought that views of how problems should be tackled might differ so much while having in mind the same reasons and goals.
Albeit I do agree that one must write tests, even if language helps, not everything can reasonably be automatically checked
wtf did i just read?
The blog post? Yeah, that was the moment I lost most of my remaining respect for his tech opinions.
Funny how he is actually now a fan of Clojure yet the examples in his book are actually full of mutating data and side effects. And Rich Hickey also stressed that tests are no silver bullet.
You can write an unmaintainable fucking mess in any language. Rust won’t save you from cryptic variable naming, copy-paste code, a complete absence of design patterns, dreadful algorithms, large classes of security issues, unfathomable UX, or a hundred other things. “Clean code” is (mostly) a separate issue from choice of language.
Don’t get me wrong - I don’t like this book. It manages to be both long-winded and facile at the same time. A lot of people seem to read it and take the exact wrong lessons about maintainability from it. I think that it would mostly benefit from being written in pseudocode - concentrating on any particular language might distract from the message. But having a few examples of what a shitfest looks like in a few specific languages might help
Java is a fine choice. Much prefer it over pseudocode.
As an example of a language that many people are familiar with, which is likely to be in long-term use where maintainability is most important, and which can almost read like pseudocode anyway, sure - probably the best ‘real language’ choice.
Prolly Clojure. He’s heavily on Clojure these days.
Honestly, a pretty fucking hilarious take. I wonder if he’s publishing a new book because the old dead tree format was boring and there’s some new crystal inscription system he read about on the forums.
if your function has more than four inputs, remember that uncle bob knows where you live
I don’t really get the hate he gets in the other comments. Are you all joking, or can someone elaborate? I always liked what I’ve read/heard of Bob.
I genuinely think his book is rubbish. I agree with some of his points. Most of the good points are common sense. For the most part I heavily disagree with the book.
Throughout the book he has examples of programs where he shows before and after he applies “clean code”, and in almost all examples it was better how it was before.
I can write a lot about why I don’t like his book. He doesn’t make many compelling arguments. It’s mostly based on what he feels is good. He often contradicts himself as well. If I remember correctly, he has a section about how side effects are bad. I agree with him on this part. Shortly after, he proudly shows an example of “clean” program - and it’s littered with awful side effects!
He also has this weird obsession of hiding the logic of the program. As a programmer, I want all relevant logic of a method to be neatly collected in one place - not scattered around deeply nested method calls.
I can go on and on. I hate this book with a passion.
I think it’s telling that none of his talks even make it all the way through his SOLID acronym, he sorta just trails off when he’s out of time.
His ideas were real big in the ruby community back when I was learning it, and if I ever go back that code is such a pain to work with. Almost impossible to follow the logic, inheritance everywhere, and I even thought metaprogramming was a good idea. Tests are the only reason that code has any reliability at all.
Now most of my code is procedural or functional, favors composition over inheritance, and is colocated as much as possible.
Fucking Ruby… Nothing is more confusing to me than seeing an error about a method not existing but the problem being that something was null/missing.
That exact error is why I only want to work in typed languages now
It’s amusing to me that people will say “my code documents itself” while also using dynamic languages. It should be called GDD. Guess driven development.
I love how parentheses on function calls in ruby are optional. Is it a variable? Is it a function? Where does it come from? Who the hell knows! Try to run it and find out, loser
death by specificity is a thing…
HTTPServletRequesthas a fuckton of methods but 90% of them could be eliminated if one treated the data as a simple fucking map instead of creating 4 methods for each key in every record of your schemas.eh, I dont mind those, they are just getters and setters
Sorry, I still don’t really get the hate.
Most of the good points are common sense.
I use what I learned from watching a talk by him on clean code and I had to learn some stuff. It might be “common sense” for experienced developers. But it certainly doesn’t come naturally that “functions should do one thing” to first time coders. The thought processes of when the software was developed usually isn’t the best way the code should be structured in the end. But that’s usually how beginners code.
It’s mostly based on what he feels is good.
In most diciplines, experience in the field is what makes the knowledge of the field. You don’t always have to be able to explain why good practice does what it does.
Also: I know of some examples, where he clearly explains his reasoning, e.g. why comments shouldn’t explain how the code works. (Because they’re not going to be updated, when the code will be)
As a programmer, I want all relevant logic of a method to be neatly collected in one place - not scattered around deeply nested method calls.
Either you misrepresent him, or you get a hard nope from me. Staying on one layer of abstraction is most likely my most important principle of writing understandable and maintainable code.
It’s mostly based on what he feels is good.
One of my main issues is, seeing his code in the past decade… It feels like this guy hasn’t coded in a collaborative environment in years.
His personal opinion tends to get on the way with code that’s easier to read from a team perspective. And “Uncle Bob” pushing that as the defacto way to code.
This happens from Influencer types who are so detached from the industry for decades and are no longer aligned with problems real engineers hit.
It’s not that he’s wrong. It’s that his perspective is outdated.
why comments shouldn’t explain how the code works
I categorize this as one of the better points of the book.
functions should do one thing
I kinda disagree with him on this point. I wouldn’t necessarily limit to one thing, but I think functions should preferably be minimal.
Throughout his examples he’s also using ideas like how functions should only be 3 lines long, preferably have no arguments, and also no return values.
This style of coding leads to programs that are nightmarish to work with. The relevant code you’re looking for might be 10 layers deep of function calls, but you don’t know where. You’re just jumping between functions that does barely nothing until you find the thing you’re looking for, and then you need to figure out how everything is connected together.
I prefer when things are flatter. This generally leads to more maintainable code as it’s immediately obvious what the code is doing and how everything is connected.
I think his book is the equivalent of a cleaning guide where all the steps are just to sweep all the mess under the carpet. It looks cleaner, but it’s not clean.
I kinda disagree with him on this point. I wouldn’t necessarily limit to one thing, but I think functions should preferably be minimal.
I do actually agree with him on that point - functions should do one thing. Though I generally disagree on what one thing is. It is a useless vague term and he tends to lean on the smallest possible thing a thing can be. I tend to lean on larger ideas - a function should do one thing, even if that one thing needs 100s of lines to do. Where the line of what one thing is, is a very hard hard idea to define though.
IMO a better metric is that code that changes together should live together. No jumping around lots of functions or files when you need to change something. And split things out when the idea of what they do can be isolated and abstracted away without taking away from the meaning of what the original function was doing. Rather than trying to split everything up in to 1-3 line functions - that is terrible advice.
Yeah, that’s an argument of semantics. I agree with you.
What I believe is that functions should do exactly what they advertise. If they do the things they’re supposed to do, but also do other things they’re not supposed to do, then they’re not minimal.
But I feel like Uncle Bob is leaning more towards that if a task requires 100 different operations, then that should be split into 100 different functions. One operation is one thing. Maybe not exactly, but that’s kind of vibes I get from his examples.
But I feel like Uncle Bob is leaning more towards that if a task requires 100 different operations, then that should be split into 100 different functions. One operation is one thing. Maybe not exactly, but that’s kind of vibes I get from his examples.
Oh yeah he defiantly does. He even says so in other advice like a function should be about 1-3 lines. Which IMO is just insane advice.
People can take the “do one thing” argument too far. I’ve seen people have individual micro services for each CRUD action on a resource.
This, but with separate services for read and write operations and another for event handling.
Yeah. I get more of what you’re saying now. The 3 line functions on principle are indeed a bit much. Although I’ve found that sometimes theare necessary to stay consistent with the layers of abstraction (e.g.: a for-loop that writes some data over some bus).
also, the dependency inversion thing makes it so that not even the tooling can help you with that, to put the cherry on the cake
Which of these do you prefer?
A?
@Test public void turnOnLoTempAlarmAtThreshold() throws Exception { wayTooCold(); assertEquals(“HBchL”, hw.getState()); }Or B?
@Test public void turnOnLoTempAlarmAtThreashold() throws Exception { hw.setTemp(WAY_TOO_COLD); controller.tic(); assertTrue(hw.heaterState()); assertTrue(hw.blowerState()); assertFalse(hw.coolerState()); assertFalse(hw.hiTempAlarm()); assertTrue(hw.loTempAlarm()); }Uncle Bob's Clean Code suggests
Option A
I almost pulled my hair out when I read that section. One is super obvious without any prior experience with the code. The other is an obscure abomination only he can understand. He’s obviously super proud of his abomination and thinks it’s a prime example of “clean code”.
It’s also a good example of how being too dogmatic about function length can hide important details.
I’ve started to prefer option A to be honest.
In C# I’m using Verify - So I prefer to just use
Verify(state);and compare the entire state against a json saved state, instead of manually verifying every individual property
Regarding the experience thing, I’d like to point out that a lot of us have experience that says „clean code” is a real pain in the ass to work with and think through.
You do? I have the opposite experience: I regularly stumple over dirty code where levels of abstraction differ wildly and I regularly lose my train of thought, because some function
writeToFile()all of a sudden shifts some bit in a register with an outdated comment next to it (overly dramatizised).Functions never being longer than 4 lines goes, too far IMHO, but the “clean code should read like prose” bit is something that has been really useful to me.
Functions never being longer than 4 lines goes, too far IMHO,
That’s the problem with the book! People experienced enough to sort out bad advice from it are already experienced enough to have learned the good advice.
Im not saying every word of it is wrong, just that the sum total of all his advice is. I don’t think there’s any school of thought that says it’s good for a function named ‚writeToFile’ to be doing other stuff
My (poorly chosen) example wasn’t about the side effects, but rather about the differing layers of abstraction. Almost all criticisms I’ve seen was about the “functions should be like only 4 lines” rule. Which admittetly: Is a bit whack. But no one actually pulls that rule through, do they?
I think the focus on short, simple functions combined with DRY code leads to many early, poorly chosen abstractions. Getting out from under a bad abstraction can be painful.
But no one actually pulls that rule through, do they?
They do though. Loads of new people to programming read that book and create unreadable messes of a code base that follow all of his advice. I have lost count of the number of times I have inlined functions, removed layers of abstraction and generally duplicated code to get a actual understanding of what is going on only to realize there is a vastly simpler way to structure the code that I could not see until all the layers and indirection are removed. Then to refactor again to remove redundant code and apply more useful layers again that actually made sense.
And that is the problem we have with his book. People that need it take up as many bad habits as they do good ones leading to an overall decline in their code quality. It is not until years of experience that you can understand the bad bits and ignore them. So overall his book is a net negative on the programming world. Not all his advice is bad, but if you can tell that then you likely don’t need his advice.
But on the layers of abstractions specifically, he takes this too far. Largely because of the 4 line limit he has. There is a good level of abstraction and I generally find more than 2 or 3 levels of abstraction is where I start to loose any sense of what is going on. He always seems to jump on abstraction as soon as he can, but I find waiting a while and abstraction when you need to to lead to fewer and vastly better layers of abstraction overall.
And adding more abstraction does not help the people of people doing too many things inside a function - they just move it to sub functions rather than extracting the behavior for the caller to deal with. I have never seen him give advice on what that is appropriate, only keeps the functionality of the original function the same and move the logic into a nested function instead and that only covers up the issue of the function doing too much.
I’m not as much vitriol as others about Clean Code, but I will argue that engineers who preach the book as some sort of scripture are really obnoxious.
I love the Single Responsibility Principle, in theory.
What I don’t like is when devs try to refactor everything to that idea to achieve “Clean Code”. I’ve seen devs over-architect a solution, turning one function into many, because they don’t want to break that rule. Then point to this book as to WHY their code is now 20x longer than it needs to be.
It also doesn’t help that every recommendation about good programming books include this.
It’s like recommending a Fitness book from the 70s - information made sense at the time, but new research has made a lot of the advice questionable.
My main issue is the whole “Uncle Bob” persona. Robert C Martin is sexist and a racist, and has been uninvited by conferences. We don’t need that type of toxicity in the industry.
Thanks. Didn’t know the last bit. Ffs =.=
It’s a beginners book filled with a mix of bad and good advice, which takes considerable experience to separate the two. Those who can point out all the bad advice already don’t need the book, and newer developers will pick up absolutely atrocious coding advice. There’s simply better books that target beginners better, like The Pragmatic Programmer.
So when you are on-boarding junior devs that have bought into the clean code/SOLID dogma, you’re spending several months beating all their terrible coding habits out of them.
While we’re giving advice on good reads, I foudn “Code Complete” to be much more useful than “The Pragmatic Programmer” (also about 10x the size).
Personally I have been around longer than him but I used to like his stuff at first.
As I’ve coded more and more on stuff that is built not only on legacy code but specifically legacy code by coders influenced substantially by clean code… damn has this single author given me a headache like nothing else ever has.
The level of inane unmaintainability and complexity achieved by younger coders being encouraged or forced to code “clean” is remarkable.
personally I’d sum it up this way: it is usually enough to abstract two parts of your code: the repetitive stuff and the stuff that can be separated from external dependencies like db or network. That should be enough to ensure readability and that you can test it properly and not have to deal with rewriting half your codebase when you decide to change an external dependency.
Can you give examples? I genuinely can’t think of how the principles applied with proper restraint not to overdo it make code hard to maintain. But I’ve only watched his talk a few years ago - not the book.
There are a fair few examples in the book itself. https://qntm.org/clean
This is the article that convinced me to never read this book. https://qntm.org/clean
I take it as people just joking. Personally I’m in doubt if the tweet is serious and the new book is true, or is it just a joke about refactoring/re-writing code.
Well engineered and ‘clean code’ are two different things. You will know when you look at it.
A well engineered codebase will always be modularized with time (-10 years)
I mean he’s walking right into this isn’t he!
He’s just refactoring it
“I’m driven by the hope that I haven’t made my best work yet” ~Paula Scher
He realized he couldn’t polish a turd.
deleted by creator
Wait he actually calls himself uncle bob? Creeper
Removed by mod








{kind=link}