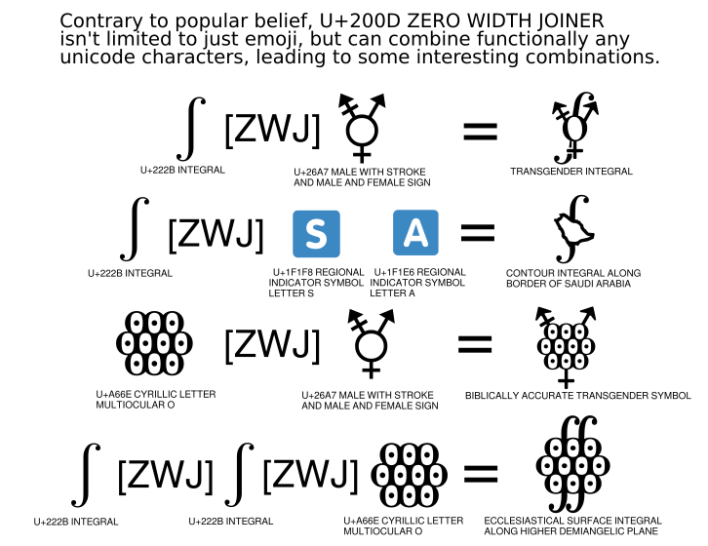
Isn’t Multiocular o the letter that as been used literally once, and yet we decided to include it in Unicode. But the original implementation had to many circles meaning we had a letter that has been used literally once and we fucked up in copying it.
Yep, exactly. After someone pointed it out on twitter, unicode consortium updated the standard to increase the number of eyes to the correct number (10), but so far I haven’t seen a single font that actually implemented the change. At least for me, ꙮ shows up with just seven eyes.
The purpose of Unicode is to be able to represent everything humans have written. Doesn’t matter if correct or not.
There are some Chinese characters that appear only once in written text, but they happen to be just typos of copying other text. They exist in Unicode.
With all of those obscure characters that they keep on adding, you’d think they’d have the decency to have separate sets for japanese and chinese characters. But nope, those are all lumped together into the CJK Unified Ideographs block. Whether a character shows up chinese-style or japanese-style depends on the font.
I have absolutely no idea about Chinese or Japanese characters, but if they did that there’s probably a technical reason like retro compatibility or something. Unicode has free space left for millions or billions of characters.
Unicode has free space left for millions or billions of characters.
I might be wrong, but isn’t unicode essentially unlimited? Like, they’re just assigning numbers (codepoints) to individual characters. Any limitation would come from encodings like utf-8, no?

{kind=link}
Isn’t Multiocular o the letter that as been used literally once, and yet we decided to include it in Unicode. But the original implementation had to many circles meaning we had a letter that has been used literally once and we fucked up in copying it.
Yep, exactly. After someone pointed it out on twitter, unicode consortium updated the standard to increase the number of eyes to the correct number (10), but so far I haven’t seen a single font that actually implemented the change. At least for me, ꙮ shows up with just seven eyes.
The purpose of Unicode is to be able to represent everything humans have written. Doesn’t matter if correct or not.
There are some Chinese characters that appear only once in written text, but they happen to be just typos of copying other text. They exist in Unicode.
With all of those obscure characters that they keep on adding, you’d think they’d have the decency to have separate sets for japanese and chinese characters. But nope, those are all lumped together into the CJK Unified Ideographs block. Whether a character shows up chinese-style or japanese-style depends on the font.
I have absolutely no idea about Chinese or Japanese characters, but if they did that there’s probably a technical reason like retro compatibility or something. Unicode has free space left for millions or billions of characters.
I might be wrong, but isn’t unicode essentially unlimited? Like, they’re just assigning numbers (codepoints) to individual characters. Any limitation would come from encodings like utf-8, no?
That’s correct. The mistake made was making an error while transcribing the same symbol into Unicode