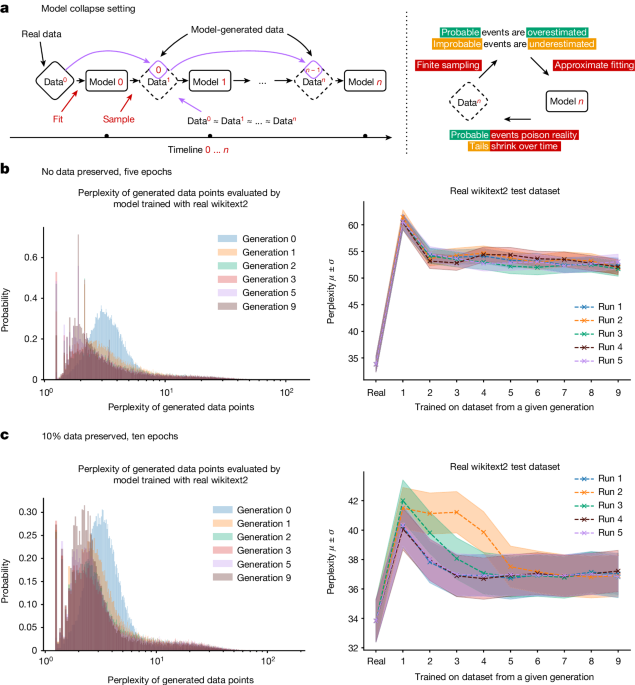
Analysis shows that indiscriminately training generative artificial intelligence on real and generated content, usually done by scraping data from the Internet, can lead to a collapse in the ability of the models to generate diverse high-quality output.
I have a similar theory. All “AIs” used right now are really just giant matrices that you multiply vectors against. It’s the same concept that’s used in computer graphics all the time, that’s why GPUs are so good for training and running them. To me a more “real” intelligence would need to grow and develop on its own completely organically without any human input and not be just a math problem. It would have to be dynamic and fluid much like a real brain. Neurons would need to function more like individual entities and behave like real neurons rather than just items in an array that get used in simple floating point operations. If you can express any core part of an “AI” as a simple function it’s not really an AI.
Note that I’m not an expert, I just spent a some years experimenting with different types and combinations of conventional Neural Networks, reading research papers and eventually came to the conclusion that they’re a dead end due to their static nature. This realization actually made me lose interest in “AI” because these things are really just “smart” input mappers that can take well educated “guesses” of what the output might be.
The best of LLMs at this point are pretty wild in how convincingly they can talk like a human and manage nuance, as well as a certain degree of creative output. But you’re not wrong in that they’re effectively just very mathy prediction engines. They can’t plan ahead because all they’re doing is predicting the next token. They don’t really know anything in the way that a human does or a database records something, they just have pre-established “confidence” in something from their training data, which might be applied more broadly or might be highly contextual to circumstance; like being able to get a height difference correct in a straightforward Q&A but failing to get it correct within the context of a fictional story.
There is also a fundamental problem, I think, in evaluating a LLM AI’s “intelligence” in particular. The primary way with which to “talk to” it is to use human language. But human language was created by humans for humans to talk about human experience and the way humans perceive the physical tactile world around them, as well as the inner worlds we have in our minds. Supposing some form of “intelligence” emerged from an LLM’s “neural networks” - how would we distinguish it as such? Its “experience” would have basically no similarities with ours and its only tool to communicate such would be through the language we use for our experiences. So it would likely just come out looking like an AI imitating a human, which naturally LLMs tend to be good at, because they need to be for the whole “language model” task to work effectively. And the more it deviated from that, the more it would likely be taken as “poor training” and in need of fixing. Add to this the fact that it can’t plan ahead, so even if there was some kind of experiencing in there, it’d have no way to string together something with intention to communicate such in the first place.
In other words, with LLMs, people are creating something which is more or less rated on its capability to communicate at the same level of effectiveness as a grown literate human, but which has virtually none of the basis that a human has. So it seems more likely LLMs will (and may already be) reaching a point of philosophical zombie stuff more so than developing unique “intelligence.”
I don’t think the underlying implementation matters that much actually. In computability theory, any system of data-manipulation rules, be it a computer’s instruction set or a cellular automaton, that’s Turing-complete is considered to be computationally universal. If what our minds do can be expressed as computation, then this process can be implemented on a different substrate.
The key in my view is that the system has to create an internal simulation of the physical world as the basis for its predictive engine, and then map language to this internal model. It’s still a stochastic system in the end, but the difference is that the language becomes a means to compress and transmit a snapshot of a far more nuanced internal state. Currently, the language is all that the model knows, and it’s just doing statistical correlation between tokens. It’s fundamentally no different from a Markov chain.


I have a similar theory. All “AIs” used right now are really just giant matrices that you multiply vectors against. It’s the same concept that’s used in computer graphics all the time, that’s why GPUs are so good for training and running them. To me a more “real” intelligence would need to grow and develop on its own completely organically without any human input and not be just a math problem. It would have to be dynamic and fluid much like a real brain. Neurons would need to function more like individual entities and behave like real neurons rather than just items in an array that get used in simple floating point operations. If you can express any core part of an “AI” as a simple function it’s not really an AI.
Note that I’m not an expert, I just spent a some years experimenting with different types and combinations of conventional Neural Networks, reading research papers and eventually came to the conclusion that they’re a dead end due to their static nature. This realization actually made me lose interest in “AI” because these things are really just “smart” input mappers that can take well educated “guesses” of what the output might be.
The best of LLMs at this point are pretty wild in how convincingly they can talk like a human and manage nuance, as well as a certain degree of creative output. But you’re not wrong in that they’re effectively just very mathy prediction engines. They can’t plan ahead because all they’re doing is predicting the next token. They don’t really know anything in the way that a human does or a database records something, they just have pre-established “confidence” in something from their training data, which might be applied more broadly or might be highly contextual to circumstance; like being able to get a height difference correct in a straightforward Q&A but failing to get it correct within the context of a fictional story.
There is also a fundamental problem, I think, in evaluating a LLM AI’s “intelligence” in particular. The primary way with which to “talk to” it is to use human language. But human language was created by humans for humans to talk about human experience and the way humans perceive the physical tactile world around them, as well as the inner worlds we have in our minds. Supposing some form of “intelligence” emerged from an LLM’s “neural networks” - how would we distinguish it as such? Its “experience” would have basically no similarities with ours and its only tool to communicate such would be through the language we use for our experiences. So it would likely just come out looking like an AI imitating a human, which naturally LLMs tend to be good at, because they need to be for the whole “language model” task to work effectively. And the more it deviated from that, the more it would likely be taken as “poor training” and in need of fixing. Add to this the fact that it can’t plan ahead, so even if there was some kind of experiencing in there, it’d have no way to string together something with intention to communicate such in the first place.
In other words, with LLMs, people are creating something which is more or less rated on its capability to communicate at the same level of effectiveness as a grown literate human, but which has virtually none of the basis that a human has. So it seems more likely LLMs will (and may already be) reaching a point of philosophical zombie stuff more so than developing unique “intelligence.”
I don’t think the underlying implementation matters that much actually. In computability theory, any system of data-manipulation rules, be it a computer’s instruction set or a cellular automaton, that’s Turing-complete is considered to be computationally universal. If what our minds do can be expressed as computation, then this process can be implemented on a different substrate.
The key in my view is that the system has to create an internal simulation of the physical world as the basis for its predictive engine, and then map language to this internal model. It’s still a stochastic system in the end, but the difference is that the language becomes a means to compress and transmit a snapshot of a far more nuanced internal state. Currently, the language is all that the model knows, and it’s just doing statistical correlation between tokens. It’s fundamentally no different from a Markov chain.