

33·
2 days agoI’m just really hoping Trump will piss off republicans in Congress fast enough that they stop supporting him before he can cause any real harm.

e
I’m just really hoping Trump will piss off republicans in Congress fast enough that they stop supporting him before he can cause any real harm.

Populism isn’t necessarily bad, business antitrust regulations and the 8 hour workday were historically populist policies. Dems shouldn’t go all out on populism, but they should do something to become popular. Elections are a popularity contest after all.
I think a big part of this might be the Democrats not wanting to take the populist pro-worker anti-rich stances due to campaign donations.
This is the second time this has happened. Democrats in the 50s-60s realized they could get votes in the North by not being racist, while Republicans at the same time realized they could get votes in the South by being racist. It just really shows that neither side really cares all that much, it’s mostly a show for political gain.
This query was most popular in Vermont.
the related queries (statistically correlated based on time, etc):
it does seem to share a lot of the worse aspects of the U.S., such as dysfunctional national transit systems

I find ChatGPT useful in getting my server to work (since I’m pretty new with Linux)
Other than that, I check in on how local image models are doing around once every couple of months. I would say you can achieve some cool stuff with it, but not really any unusual stuff.
Oh, I had some of those last year on some lemmy thread somewhere.




honestly, its pretty good, and it still works if I use a lower resolution screenshot without metadata (I haven’t tried adding noise, or overlaying something else but those might break it). This is pixelwave, not midjourney though.
If I pay $60 for a game, I want to be able to play it in at least 10 years, not just 3.
shocking: users of open-source reddit alternative like open-source things
Probably TMNF lol
Unless you like unreasonable subscription models
Can’t you do that with any search engine?

Archinstall is super easy. Just copy a few commands from the wiki to join a wifi network and then it will take everything from there.

22?
quick test, with that prompt and flux schnell gguf 4 bit again:
it seems a lot stupider than pro lol
I thought this couldn’t be true, so using one of the newer models (4bit flux) I told it to make a 5 sided star, and then put lines around the outside
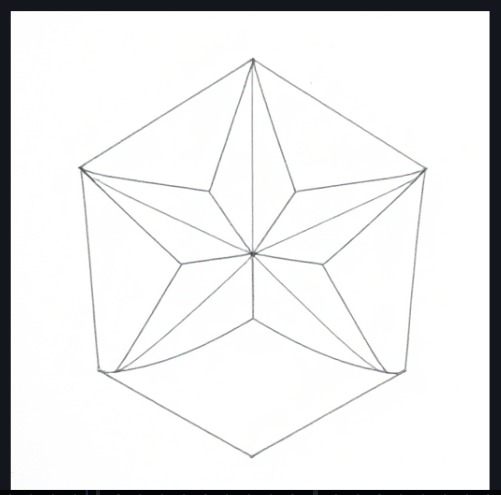
lol this is very weird, did they forbid it from looking at pentagons in the training data or something? it can’t do The Pentagon either, it gives it 8-12 sides instead
If firefox becomes worse or starts lagging behind more, I’ll stop using it. It doesn’t seem all that useful to attempt to predict 5 years into the future Firefox’s state and therefore decide to switch away now.
All browsers are either based on KHTML or Netscape. There’s no alternative.
You see that’s a sort of weird way of looking at it?








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
its developed by Mozilla