It was shared on GitHub on Sunday July 22 by lemmy.ca staff. Developers who run the project do not seem to do merges on Saturday and Sunday. I submitted a pull request Sunday evening given the server crash relief this would provide, ready for them first thing Monday. I clearly labeled the pull request as “emergency”.
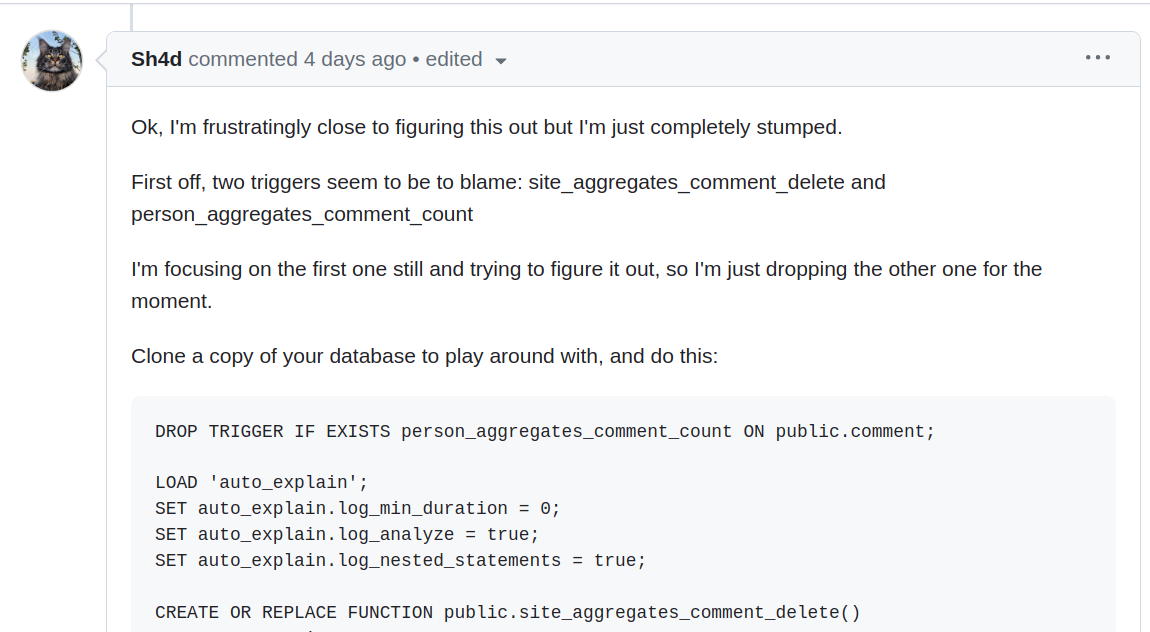
It is well into Wednesday and merges are being done on new site features for for the past 3 days. Yet, server crash pull request was edited to remove “emergency” from description first thing Monday and sits without any urgency attention.
This is the same pattern I saw for the past 2 months regarding server crashes related to PostgreSQL.
Previous fixes before the Reddit deadline of end of June were not rushed in to prevent crashes. And this week Elon Musk renaming Twitter to X has been a big influx to the federverse… yet servers are crashing from these SQL UPDATE flaws.
I go by my post yesterday, it’s all some kind of social hazing convention to new users of the Lemmy platform. Lemmy has been around since February 14, 2019 on GitHub. it is not a new app. But the app running on sites since 2019 did not have significant amounts of data (post and comments) until May or June 2023.
I personally feel like I failed because I didn’t understand pg_stat_statements was ignoring stored procedures/functions without an additional parameter. Ooops. Sunday GitHub activity from lemmy.ca staff was my wake-up call on that missing parameter.
For developers so concerned to keep you “on topic” and “not to bring up things outside the scope of their issue” on GitHub… they sure do not seem to care about the technical reputation of Lemmy as a platform throwing errors all over the front page, app clients, and the delivery of messages, meeting their own promise of deleting (“full delete”), and their own promise of “high performance”. Crashes caused directly by the Account Delete are in fact what the fixes I pull requested on Sunday are intended to address. Very concerned with how a human being interacts on GitHub comments, they are very concerned you use Matrix to talk to other developers (and ignore Lemmy postings about server crashes / constant SQL related failure errors), but not at all concerned about the unwashed non-developer masses of people who try to use Lemmy and get crash errors.
I still think it’s a form of social hazing being played on newcomers. Some kind of anti-establishment social hazing, to watch for over 2 months as flocks of users come from Reddit frustrations and Elon Musk “X” renaming - to not have any sense of priority in fixing the SQL with server crashes. Tuning off aggregate counting PostgreSQL triggers would have been an immediate crisis mitigation. The developers know the 4 year history of all the code and how those April 2022 TRIGGER functions can be removed, but they seem to want the hazing social approach to play out on the newcomers from Reddit, Twitter, etc.
Fresh example, users here on Lemmy reporting that Join-Lemmy is 502 nginx errors, This kind of total crash for the project has been normalized for the 62 days I have been testing Lemmy at least 3 hours each and every day. https://lemmy.ml/post/2482662
Day 62, fresh from GitHub, it’s got to be social hazing at play, right?
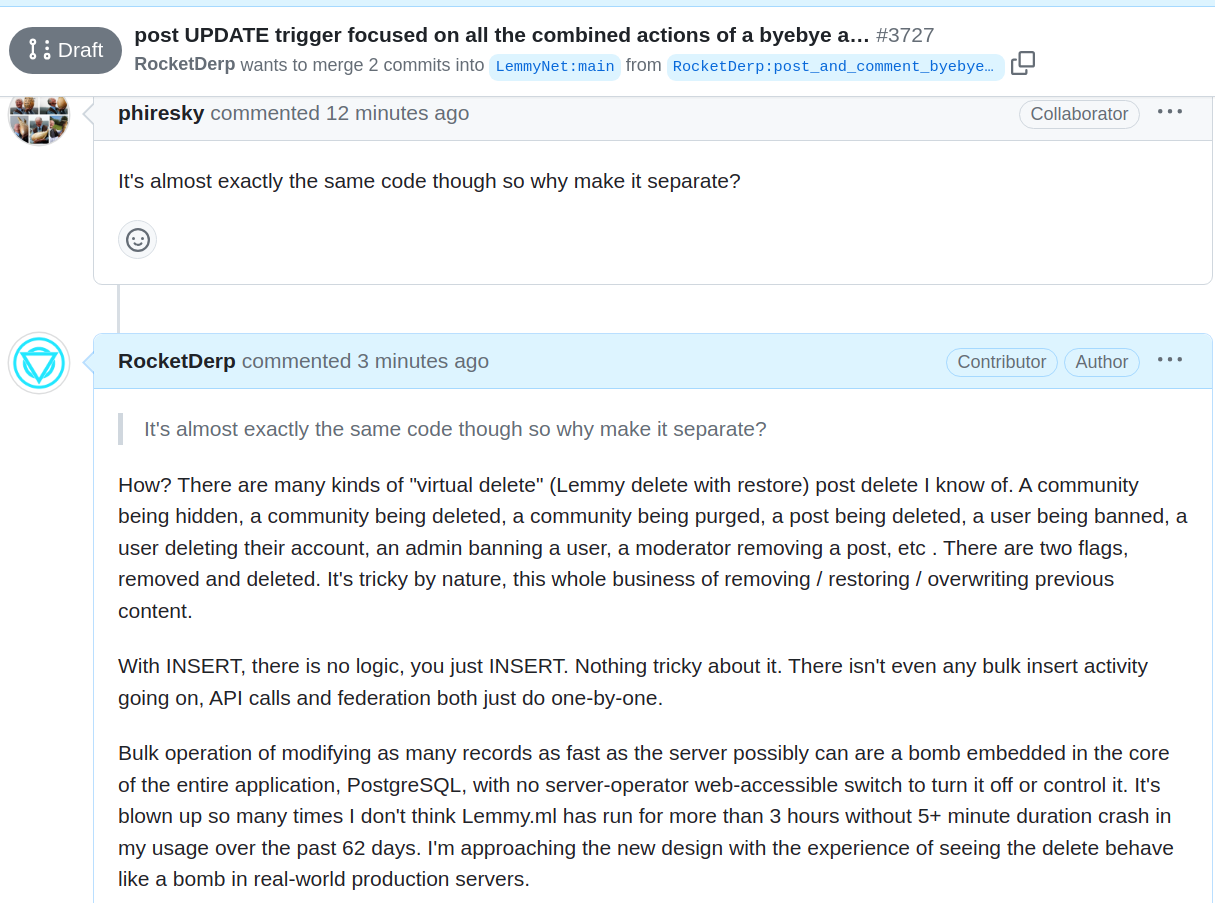
I’ve really never encountered social hazing like this being played on the entire Twitter, Reddit community coming to Lemmy. It’s so unusual to witness the bragging of “high performance” and “full delete” while behind the scenes this kind of attitude towards constant server crashes is going on.
Somehow it is a social hazing game where performance is cited, but the fact that nobody looked at the broken TRIGGER for 60 days while servers were crashing - code readability and attention on the “bomb”… isn’t a social factor of the developers and project leaders. But the social hazing of the entire Twitter and Reddit communities coming to Reddit seems more likely to explain the responses. Servers were crashing with PostgreSQL hangs and overloads, and for 60 days nobody looked at the TRIGGER statements and saw an obvious problem with a wide-open runaway UPDATE lacking a WHERE clause.
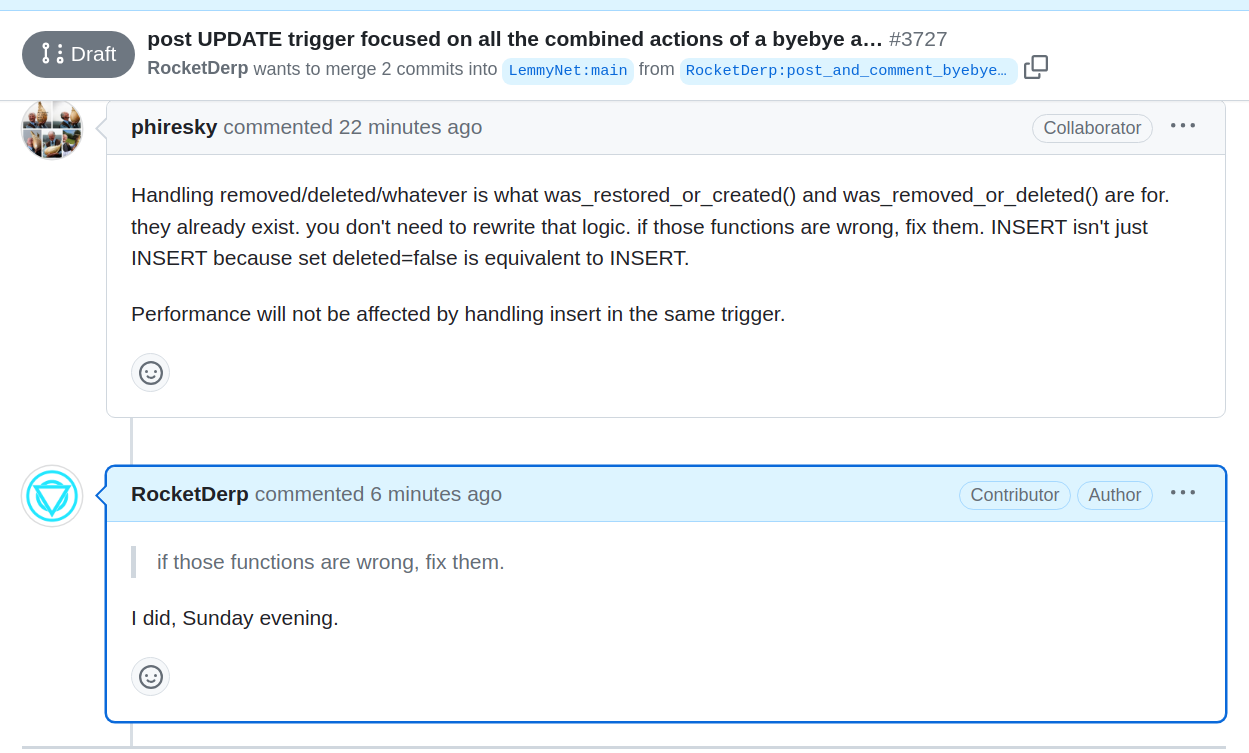
So, now the conclusion is that other instances do not matter, and that there was no reason for site_id field to be in the design of the table itself. That is how they are reading the code…
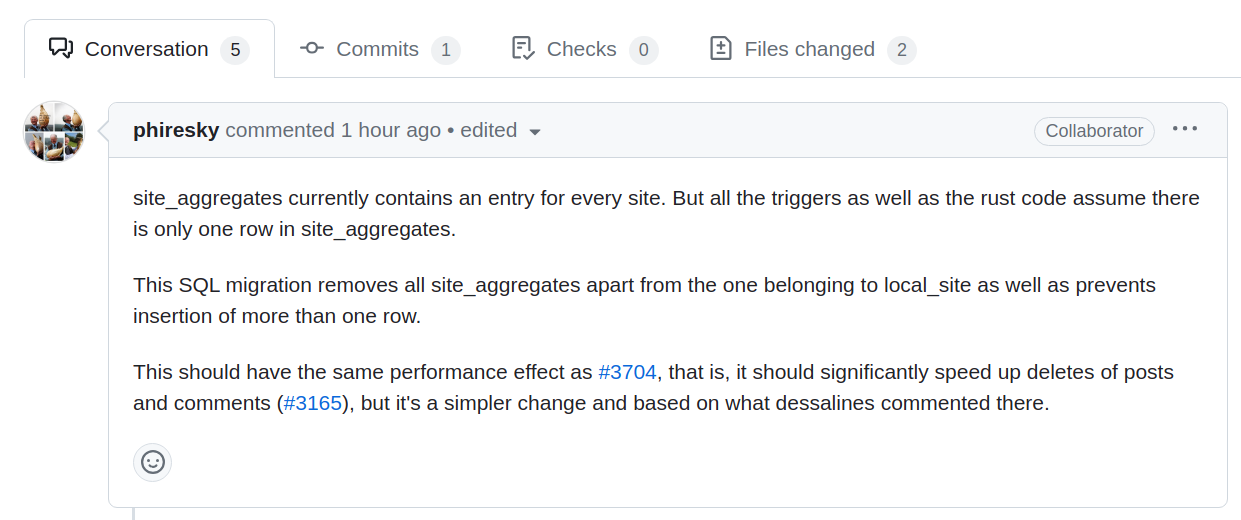
I spent all my time commenting out loud on GitHub on Sunday explaining why I thought the design was fine, and the UPDATE with no WHERE clause was a mistake.
Further, the going-backwards approach is to remove federation. To act like Reddit, a site that does not federate. The going-forwards with federation approach is to start having many rows updated in site_aggregates by replicating them with other instances and having information about remote persons, remote communities, remote sites (instances, site_aggregates) updated every hour, or 4 hours, or 12 hours.
Further, they seem to think that the performance issue is ONLY with deletes. In fact, the bug is there with INSERT of comment and INSERT of post. Which is hammering PostgreSQL by updating 1700 rows of site_aggregates with count = count +1 change that lacks a WHERE clause! I spelled this out Sunday! But this Wednesday comment from 2 hours ago on GitHub implies that the only performance issue is only of concern regarding DELETE. DELETE isn’t even that common of a transaction in the world, people mostly do not delete their comments and posts. The disk I/O of writing the UPDATE to 1700 rows of site_aggregate data is WAY MORE than the INSERT into the comment table of the comment itself! The concurrent users, doing their constant post creation and comment creation, are creating a locking nightmare on that TABLE in contention for constant updates while the DELETE is a rare event that smashes into those locks.
Is this more social hazing?
Long Distance Runaround, this is elaborate hazing going on against the entire social media of the World Wide Web… to ignore the server crashes systemically for 60 days and even when I personally create corrected PostgreSQL TRIGGER FUNCTION updates on Sunday evening… be well into the workday Wednesday not deploying the trivial fix/change. Let alone, seeing PostgreSQL falling over constantly and existing developers not reviewing or drawing attention to the TRIGGER code and logic (or only mention it in a casual GitHub issue). I’m a project newcomer, they have been working on it for 4 years and knew about the behind-the-scenes (hidden) PostgreSQL TRIGGER functions.
It is hazing, right? It has to be social hazing. They have known since June 4.
I still remember that dream there… https://www.youtube.com/watch?v=ZS-k02hf-hI … count to one hundred.
Long distance runaround Long time waiting to feel the sound I still remember the dream there I still remember the time you said goodbye Did we really tell lies Letting in the sunshine Did we really count to one hundred Cold summer listening Hot color melting the anger to stone I still remember the dream there I still remember the time you said goodbye Did we really tell lies Letting in the sunshine Did we really count to one hundred Long distance runaround Long time waiting to feel the sound I still remember the dream there I still remember the time you said goodbye Cold summer listening Hot colour melting the anger to stone I still remember the dream there I still remember the time you said goodbye Did we really tell lies Letting in the sunshine Did we really count to one hundred Looking for the sunshine