


Thanks to @sailor_sega_saturn@awful.systems for this manmade horror within my comprehension. Initially I wanted to respond in that thread but this is far too long, so enjoy my yet another descend into madness.
So this post tackles philosophy, physics, and computer science (specifically information theory). I’m not a philosopher so I’ll mostly disregard those parts. I’m also not a physicist, but fortunately enough the physics here is so bad and stupid a high-schooler’s understanding of entropy suffices. As for information theory, well, the author’s fucked cause I know what those words mean.
Bad philosophy
While inherently speculative, the simulated universe theory has gained attention from scientists and philosophers due to its intriguing implications.
Has it though? Are the implications really that intriguing, beyond a “that’s wild duuude” you exhale alongside the weed smoke in your college dorm?
Then there’s something about Matrix and Plato, whatever, and
In both cases [of Plato and modern philosophy], the true nature of reality transcends the physical.
Within the scientific community, the concept of a simulated universe has sparked both fascination and scepticism.
Okay, this is contradictory on its face. If simulation theory tackles things that “transcend the physical” then the scientific community by definition has absolutely no interest in it, because science is concerned only with physical reality. You know, things you can actually do science on. If your theory is in any way testable, it, again by definition, has to be within the physical realm, cause that’s the only thing we can measure! The author doesn’t even reference any metaphysical mumbo jumbo anywhere further, so this is just padding the word count. Also, it’s “skepticism”.
Some scientists suggest that if our reality is a simulation, there may be glitches or patterns within the fabric of the universe that betray its simulated nature. However, the search for such anomalies remains a challenge.
Lol. The search for Bigfoot remains a challenge.
Ultimately, we lack a definitive framework to distinguish between simulated and non-simulated reality.
Shame that this article doesn’t propose one either.
If our physical reality is a simulated construct, rather than an objective world that exists independently of the observer, then how could we scientifically prove this? In a 2022 study, I proposed a possible experiment, but it remains untested today.
Let’s just :pin: that for now, we’ll come back to that later.
However, there is hope. Information theory is the mathematical study of the quantification, storage and communication of information. Originally developed by mathematician Claude Shannon, it has become increasingly popular in physics and is used a growing range of research areas.
This definition is also the first sentence of Information theory on Wikipedia. I cannot evaluate the claim of becoming increasingly popular in physics, but sure, information theory is a real field and is extremely useful. Such a shame the author knows jack shit about it.
In my recent research, published in AIP Advances, I used information theory to propose a new law of physics, which I call the second law of infodynamics. And importantly, it appears to support the simulated universe theory.
Another :pin: into that research, but come on. First of all, “infodynamics” is just… cringe, there’s no other word for it, this makes me cringe, it’s embarrassing.
Second… ye, why is it the second law of infodynamics? What’s the first one? Does the author know that the second law of thermodynamics is the second one because there’s a first law of thermodynamics??
It only gets worse from here.
Bad physics
At the heart of the second law of infodynamics is the concept of entropy – a measure of disorder, which always rises over time in an isolated system.
NO! Entropy is not a “measure of disorder”. It’s a common misconception (charitably we could call it a simplification), but you absolutely cannot say this if you’re trying to say something serious about physical laws. To make it obvious, the author provides a direct refutation in the very next sentence:
When a hot cup of coffee is left on the table, after a while it will achieve equilibrium, having the same temperature with the environment.
This is correct (if simplified), that is indeed the state of maximum entropy if we consider say the room to be completely isolated. But… is a cold cup of coffee more disorderly than a hot one? It’s grosser, but not disordered. If anything, at a physical level a hot cup full of particles speeding around sounds more chaotic than a cold one. Moreover, the author will later prove they have no idea that there is a big difference between a cup of coffee in and of itself being considered as an isolated system, versus a system of an entire room with a table and a cup, which is a fatal mistake.
A useful intuition for us regarding entropy is that it’s a measure of how close to a completely uniform distribution of particles we are. The state with the highest entropy is the one that is the most likely to arise if you just distributed particles uniformly at random, while the total mass and energy are constrained. Low entropy states, on the other hand, are the ones less likely to get drawn from a random distribution. So, a room in which everything is roughly the same temperature has higher entropy than one in which there’s a bunch of much hotter particles concentrated in a small volume of the cup – if you were just randomly distributing matter around the chance of getting a cup of hot coffee is quite low. 1
This intuition will later apply to information entropy as well, so keep it at the back of your head. Now, this:
The entropy of the system is at maximum at this point, and its energy is minimum.
This is still about that cup. The first part is roughly okay, but obviously the total energy hasn’t changed. The heat of the coffee didn’t evaporate, the air in the room is now slightly warmer because it absorbed it! This, by the way, is the FIRST FUCKING LAW OF THERMODYNAMICS, the energy of an isolated system is constant!
Bad computer science
Okay, end of physics. Let’s get into the main point – information theory. This is where it gets the funniest to me because misunderstanding maths and pushing it as some kind of radical philosophical insight is just comedy gold for the very specific kind of freak I am.
The second law of infodynamics states that the “information entropy” (the average amount of information conveyed by an event), must remain constant or decrease over time – up to a minimum value at equilibrium.
Entropy in information theory also has a rigorous definition, and its formula isn’t even that scary if you’re not completely allergic to maths. We’re considering probability distributions and we have a single random variable X. This can be a coinflip, a die roll, any random process. The variable has the domain of D, which is simply the set of its possible values, so {heads, tails} for a coinflip, or
{1, 2, 3, 4, 5, 6} for a d6, etc. The probability distribution is p: D -> [0, 1], so the chance for a given event, for example p(heads) = p(tails) = 0.5. The entropy of X is then:

That’s it, it’s just a value. It’s always positive, but can be zero. For example, the entropy of a cointoss with equal probabilities for both sides is 1:

The intuition from physics that the highest entropy states are the ones that are the most uniform also applies here! If we bias the coin so that now heads has probability $0.75$ we get smaller entropy:

Finally, a completely predictable variable, where one event has probability 1, has an entropy of zero. We will call such a probability distribution trivial.
So the problem with the statement of this “second law of infodynamics” is that it tries to describe change, but doesn’t say of what. Entropy only makes sense for a given probability distribution. If the distribution is fixed, entropy is fixed. If it changes, its entropy changes accordingly. So if this law tried to say something about probability distributions, it’d be that “probability distributions tend towards trivial”. This is a weird claim, but so far we only saw the statement. If you’re thinking there’s a proof later on then lol, no there’s not, go fuck yourself. This is just stated and then asserted throughout with absolutely no basis in reality.
So it is in total opposition to the second law of thermodynamics (that heat always flows spontaneously from hot to cold regions of matter while entorpy [sic] rises). For a cooling cup of coffee, it means that the spread of probabilities of locating a molecule in the liquid is reduced. That’s because the spread of energies available is reduced when there’s thermal equilibrium. So information entropy always goes down over time as entropy goes up.
This is the problem with analogies, especially poorly constructed ones, they have pretty limited explanatory power if you don’t set up the formalism first. I’m not sure what “spread of probabilities” means here, but “locating a molecule in the liquid” is not a meaningful probabilistic question in this setting. If your system is just the cup of coffee and we have a simplified model where it’s isolated from everything else, then it is already roughly in thermal equilibrium! Its entropy is almost maximum! It doesn’t matter if the coffee is scorching hot or if it’s frozen – the entropy of just the coffee in the cup at 80 degrees is the same as at 20 degrees. The temperature, pressure, and volume of the system are parts of its macrostate, which entropy doesn’t describe. They’re assumed fixed, the question lies in the microstate, which is the arrangement and momentum of all molecules that are possible within the macrostate. For example, the coffee being all pooled together in one half of the cup, leaving vacuum in the other, is a very unique state and has low entropy. Coffee being kinda all over the cup uniformly at random is the high entropy state.
The state you should be considering to have changing entropy is the one where we have a cold room in which the coffee is placed. But then surely the probability of locating a molecule in the cup is still not any different if the cup is hot vs if it’s at equilibrium. Nothing actually happened to make the arrangement of molecules in the cup any less uniform.
Finally, the last sentence is a complete non-sequitur. Where did information entropy come in here? Are we talking about the entropy of the location of particles in the cup, treated as a random variable? Well then this is doubly false, because in this example both the high and low (physical) entropy states of the room have essentially the same distributions, but also if you were to take a much lower-entropy physical state – say all of the coffee molecules being squished in one half of the cup – then the information entropy of their position distribution also becomes lower! Clearly we skewed our distribution so that for all points in one half of the cup is roughly doubled, while for the other it’s now zero. As we demonstrated above, moving away from a uniform distribution decreases information entropy. In a discrete case, let’s say that there are 2N possible placements of a molecule in the cup. If the distribution is uniform then the entropy is

If, however, half of the placements are impossible and all others are twice as possible, we get
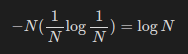
Which is clearly lower! The converse is also true, so if you somehow smushed together all coffee to one side (creating a low entropy state) and then released it to mix freely (increasing physical entropy), you’d move the placement probability distribution towards uniform and thus also increase information entropy.
If you consider the molecule placement to be a continuous distribution you’d need to move to a different definition of entropy with integrals and shit, I’m not doing that, but it’s essentially the same argument.
My study indicates that the second law of infodynamics appears to be a cosmological necessity. It is universally applicable with immense scientific ramifications. We know the universe is expanding without the loss or gain of heat, which requires the total entropy of the universe to be constant.
It doesn’t. Why would it? I don’t really have anything else to say here, the energy stays constant, but a system with constant energy can still change its entropy, THAT IS LITERALLY THE WHOLE POINT OF THE SECOND LAW OF THERMODYNAMICS!
However we also know from thermodynamics that entropy is always rising. I argue this shows that there must be another entropy – information entropy – to balance the increase.
Lol, so now we’re treating these entropies as if they could “balance” each other? That’s rad. The unit of information entropy is bits (pedants might call them “shannons” but whatever). The unit of physical entropy is JOULES PER KELVIN. I have no idea how you want to “balance” bits and $kg m2s{−2}K^{−1}$, but good luck.
Bad biology
My law can confirm how genetic information behaves. But it also indicates that genetic mutations are at the most fundamental level not just random events, as Darwin’s theory suggests. Instead, genetic mutations take place according to the second law of infodynamics, in such a way that the genome’s information entropy is always minimised. The law can also explain phenomena in atomic physics and the time evolution of digital data.
The first link is a citation to another paper of the author, while the link under Darwin is, I shit you not, an encyclopedia entry of Natural Selection in National Geographic xD
Anyway, Darwin never posed that mutations are “random” in any probabilistic sense of the word so this is horseshit. The author again has issues with defining which probability distribution they consider, so I’m not sure if by “genome’s information entropy” here they mean the distribution of genomes throughout a population (where the genome is the random variable) or just the distribution of ATCG in a single genome. The first alternative is funny because it would posit biodiversity decreases over time as we all converge onto some ubergenome. The second is hilarious because it means that the ultimate genome we’re drifting towards is all As (or all Ts, or all Cs…). I don’t know shit about biology, but I’m around 99 joules per kelvin convinced that’s not a useful genome.
Most interestingly, this new law explains one of the great mysteries of nature. Why does symmetry rather than asymmetry dominate the universe? My study demonstrates mathematically that high symmetry states are the preferred choice because such states correspond to the lowest information entropy. And, as dictated by the second law of infodynamics, that’s what a system will naturally strive for.
A state doesn’t correspond to lower or higher information entropy because a state is not a probability distribution. States don’t have informational entropy! Also, the corollary of the second law of thermodynamics is that the ultimate state of the universe is HEAT DEATH, where the state is a completely random scattering of molecules that can no longer perform any work. It’s noise, not symmetry. And you should know that, since your intuition behind entropy is a “measure of disorder”, hence symmetry dominating the universe would contradict “disorder” increasing. And distributions that look like that actually have quite high information entropy, since as we established the distributions with highest possible entropy are the uniform ones, also known as NOISE.
I believe this discovery has massive implications for genetic research, evolutionary biology, genetic therapies, physics, mathematics and cosmology, to name a few.
Since you’ve just demonstrated a complete lack of understanding of all of those topics this is, to put it mildly, dubious.
Oh, but we need to come back to the topic of the article
Bad everything
Simulation theory
The main consequence of the second law of infodynamics is the minimisation of the information content associated with any event or process in the universe. This in turn means an optimisation of the information content, or the most effective data compression.
This is, of course, completely backwards. It is the case that distributions with high entropy are the ones hardest to compress – this is the main motivation behind Shannon’s work and led to the Source Coding Theorem that essentially states that to encode messages from a given distribution $X$ you need, on average, $H(X)$ bits. However, since all of your reasoning is reversed for some reason, the opposite would be true. To encode the full state of a dead universe you’d need to meticulously write down the position and momentum of every single molecule, since there’s no “pattern” to notice and compress.
Since the second law of infodynamics is a cosmological necessity, and appears to apply everywhere in the same way, it could be concluded that this indicates that the entire universe appears to be a simulated construct or a giant computer.
This is just great, dude made up a whole new law of physics and led us through a myriad of misconceptions and non-sequiturs just to arrive here and… pull the simulation thing right out of their ass. WHY? Why do you think this is the conclusion? On what fucking basis?? Because entropy low???
A super complex universe like ours, if it were a simulation, would require a built-in data optimisation and compression in order to reduce the computational power and the data storage requirements to run the simulation. This is exactly what we are observing all around us, including in digital data, biological systems, mathematical symmetries and the entire universe.
Only that we are not, so by your logic we’ve disproven the simulation hypothesis. Good job guys, didn’t think we had it in us but here we are.
Further studies are necessary before we can definitely state that the second law of infodynamics is as fundamental as the second law of thermodynamics. The same is true for the simulated universe hypothesis.
Maybe further studies could shed some light on the missing first law of infodynamics, or even define what “dynamics” does in that word.
But if they both hold up to scrutiny, this is perhaps the first time scientific evidence supporting this theory has been produced – as explored in my recent book.
Of fucking course it is. The book description is great too
The author (…) [offers] unique perspectives and novel scientific arguments that appear to support the hypothesis.
“Appear” holding that sentence up puts Atlas to shame.
Those studies
So let’s unpin those two “studies”. First, the proposed experiment to falsify the simulation hypothesis. Let me just show you the tasty bits:
In 1961, Landauer first proposed the idea that a digital information bit is physical and it has a well-defined energy associated with it.[5,6] This is known as the Landauer principle and it was recently confirmed experimentally.[7–10]
The Landauer principle says that there is a minimal energy cost associated with computation, so that writing a single bit of infromation requires non-zero energy. As far as I can tell it’s widely accepted, but not actually confirmed experimentally. In fact one of the cited papers here claims to have violated the Landauer limit during their experiment. In any case – whatever, the claim is not that far out there.
In a different study, using Shannon’s information theory and thermodynamic considerations, the Landauer principle has been extended to the Mass–Energy–Information (M/E/I) equivalence principle.[11] The M/E/I principle states that information is a form of matter, it is physical, and it can be identified by a specific mass per bit while it stores information or by an energy dissipation following the irreversible information erasure operation, as dictated by the Landauer principle.[5,6] The M/E/I principle has been formulated while strictly discussing digital states of information. However, because Shannon’s information theory is applicable to all forms of information systems and it is not restricted only to digital states, the author extrapolated the applicability of the M/E/I principle to all forms of information, proposing that information is the fifth state of matter.[11,12] These ideas, regarded as the information conjectures, are truly transformational because, without violating any laws of physics, they offer possible explanations to a number of unsolved problems in physics, as well as complementing and expanding our understanding of all branches of physics and the universe and its governing laws. Hence, testing experimentally these information conjectures is of extreme importance.
I will let you have one guess who is the sole author of the sole paper that introduced this revolutionary M/E/I principle :)
The first proposed experiment to test the M/E/I equivalence principle involved the measurement of the mass change in 1 Tb data storage device before and after the digital information is completely erased.11 At room temperature, the calculated mass change for this experiment is in the order of ∼10−25 kg, making the measurement unachievable with our current technologies.
Do you remember how people put dying folks on weights so that they could see if a soul escaping the body had mass? I’m not saying this is dumber, but it’s still pretty dumb.
The rest of the article describes the method using a lot of symbols. To summarise, the claim here is that each elementary particle contains some non-zero number of bits of information about itself, and thus annihilating an electron and a positron should release not only the energy of the physical forces, but also the energy of the information itself.
The rest of the paper is highly technical and describes the setup for the proposed experiment and I have no chance of actually evaluating it. However, after skimming, I can at least say that it doesn’t seem outlandish? Like someone could just run it in a lab and actually reject the guy’s hypothesis, so hey, this at least smells like actual science, even if the claim is highly dubious.
The core study, “Second law of information dynamics”, tries to argue its point by setting up an experiment where the word INFORMATION is written in binary using magnetic recording. Over time, the magnetisation dissipates, leading to the word being erased. There’s even a nice picture:

Now there’s not that much to sneer at, but I’d like to point out the critical flaws with this. First, the author defines Shannon’s information entropy and then writes this:
Using (2) and (3), we can deduce the entropy of the information bearing states from the Boltzmann relation,
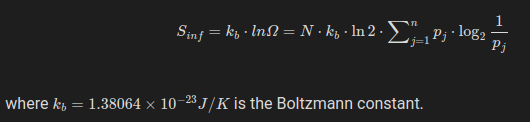
This equality is not justified in any way. The left-hand side is the Boltzmann formulation of physical entropy. Then the author just plugs in Shannon’s entropy into Omega without justifying that this transformation makes any sense. This is the central claim, though, you are trying to tie together physical and information entropy, and the way you did it is by just forcing one into the other! If information is a physical quantity then it also has a unit (bits), so S_inf is now in Jbits/K and you cannot equate it with any other “regular” physical entropy in J/K anyway.
The second issue is that information is never well-defined here. If you look at the picture above you might see “information” in the sense that there’s some patterns you can recognise as a message, and then it disappears. Looks like information was lost! But this is only accurate if you consider the picture to be made out of an 8 by 11 grid of units that are there and then disappear. That makes sense from an information-theoretic perspective, but from a physical perspective the picture is made out of bajillions of molecules that compose the microstate! If as information you consider the state of these molecules, then in (b) it’s a highly ordered macrostate, where the probability distribution only allows microstates that look roughly like INFORMATION encoded in binary (low entropy), and dissipates until it’s just random noise in (h) (high entropy).
In other words, the author picks what they consider to be information, set that as the set of observable events, and then concludes that because they as a human observer can no longer discern the message they encoded the amount of information in the picture had to decrease.
Wtf is AIP Advances?
So these two were published in American Institute of Physics Advances, which looks like a serious journal about physics. Does anyone know about it? It occupies a space where I can’t easily find any obvious issues, but I also can’t find anyone saying “ye this is legit”. It claims to be peer-reviewed, and at least isn’t just a place where you dump a PDF and get a DOI in return.
Chaser
Dr Melvin Vopson, author of the article, published one thing in 2024, which is

Disclaimer
Btw Dr Vopson seems to have done quite a lot of research in other fields that I have absolutely zero idea about (I think mostly material science) and I don’t really think he’s a crank. Just from reading the paper it’s clear that he knows way more than your average weirdo, like experimental setup and magnetic properties of things I can’t pronounce, so I’m sure he’s a good material physicist. It just seems he fell into a rabbit hole of simulated universe and veered too far away from his field. I’m not so sure how to square that with the blatant misrepresentations of thermodynamics in the article, though.
1 If actual physicists want to fleece me in the comments for misrepresenting entropy, go ahead (no really, I love learning more about this shit), but I’m rather sure this isn’t an egregious simplification.
The thing already is a markdown renderer and every single markdown renderer I encountered supports maths within
$delimiters.yeah lemmy’s got some real weirdo choices
it may be possible to reconfigure lemmy’s markdown renderer to shunt anything (within reason) between
$s to mathjax; I wouldn’t mind looking into that once we restart development on Philthy.in the meantime, as an inadequate compromise, you can enable mathjax on gibberish.awful.systems blogs and get better rendering for a long-form math-heavy article there. the unfortunate trade-off is you’ll lose the ability to upload images and they’ll have to be PRed into the frontend repo if you want them local (yes, that’s really the recommended way to do it in bare WriteFreely, unless you’re on their paid flagship instance where they spun up a private imgur clone to handle it).
if there’s interest and PRing images in (or using an upload service elsewhere) isn’t doing it, we can look into doing a basic authenticated upload into object storage kind of service. (or maybe there’s a way to hack pict-rs into doing it? I don’t like pict-rs, but it is our image cache)