
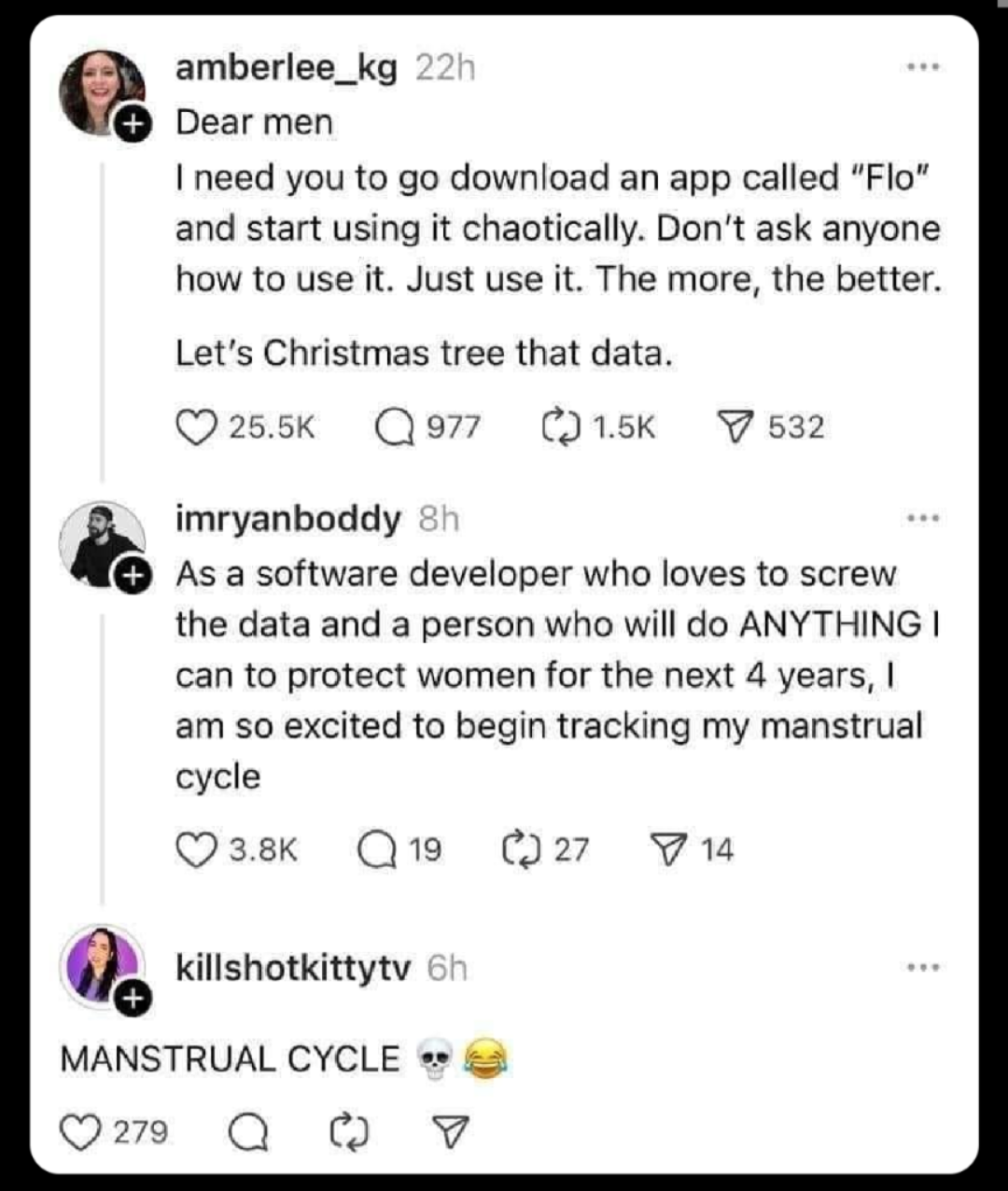
{kind=link}
There are downsides with downloading their app just to input bad data, but it’s a fun thought.
edit: While we’re at it we might as well offer an alternative app to people.
I posted in !opensource@programming.dev to collect recommendations for better apps
The post: https://lemmy.ca/post/32877620
Leading Recommendation from the comments
The leading recommendation seems to be Drip (bloodyhealth.gitlab.io)
Summarizing what people shared:
- accessible: it is on F-droid, Google Play, & iOS App Store
- does not allow any third-party tracking
- the project got support from “PrototypeFund & Germany’s Federal Ministry of Education and Research, the Superrr Lab and Mozilla”
- Listed features:
- “Your data, your choice: Everything you enter stays on your device”
- “Not another cute, pink app: drip is designed with gender inclusivity in mind.”
- “Your body is not a black box: drip is transparent in its calculations and encourages you to think for yourself.”
- “Track what you like: Just your period, or detect your fertility using the symptothermal method.”
Their Mastodon: https://mastodon.social/@dripapp
Computer databases are kind of purpose-built to organize a lot of (arbitrary) information. I seriously doubt this kind of chaos is going to make even the slightest difference. It’s probably just giving people some false sense of security while any information that’s stored in any cloud can still be retrieved. And effortlessly be matched to whomever they like to oppress. At least if it’s associated with some account, email or specific phone.
“A bunch of new accounts posting obviously worthless data joined about the same time. Disregard them.”
So you’re saying if a woman made an account during this time, and threw garbage data in, they’d disregard it and then a month later she could use it for real?
(Also you guys are hilarious about how quickly you can just ‘do that’ because I’ve never worked at any software company where the devs who made the initial code are even still at the company a year or two later.)
This is data analysis, not development. Yes you can just exclude the problem month, average the previous and next months, and her real data starts to contribute again. And yes you can do that regardless of who is writing code. Or even that the code was written by your company and not some other company you bought or seized data from.
probably won’t be hard to spot all the accounts that sign up en masse, send 3 data points then stop forever because they got bored or forgot.
Alright, sure. The company will rigorously dig through the data to exactly remove exactly the specific accounts that aren’t real and deftly deal with it, and it won’t be some intern with a weeks training in paper docs from three years ago. No, it’ll be people who will know to do exactly those things. And the data you’re scraping to sell, well, no-one will mind you splicing out data you claim isn’t real and was fake, no they’ll be fine with that. Then when that intern is gone–and they didn’t log anything because they were never taught to–and the new intern arrives, they’ll know to continue exactly where they should, and at no point will anyone fuck up the dates, times, or additions from previous months. At each and every stage exactly what has to happen will happen, and no code changes, updates, or manager-directives will change any of these parts in any way. The addition of anywhere from dozens to hundreds to even tens of thousands of new accounts will be easy to deal with, because this has all been prepared ahead of time, and will immediately be dealt with. It won’t take weeks of meetings on how to tackle it, by whom, and what to push back - because they use waterfall/agile, and it’s a foolproof system where you don’t just punt things forward, you deliberately and delicately lay out each and every change that will now take place mixed with the 2 years that have already been planned out.
Absolutely everything will be covered and not a single thing will get through, and they’ll carefully and easily parse through the data with zero issues on the demand of a very competent government that doesn’t show any signs of issue whatsoever.
Nah they’ll just say “weird. Guys, exclude November, it’s an outlier”.
Okay cool, so the women who make accounts then can still use them, awesome.
Yes absolutely they can
You know the purpose of this is so they can use them without being tracked though, right? If it’s easy to exclude outliers and bad data, it makes this suggestion pretty useless.
As people have suggested, there’s almost no reason to ever have this data leave your own personal device or network. Women have tracked their periods for thousands, maybe hundreds of thousands of years.
I’m willing to bet it uses something resembling an SQL database on the back end, so ignoring or deleting data or entire user accounts that signed up in November 2024 should be a matter of a query or two.
I would also like to point out that, much like the Republicans, you’re painting your enemy as both dangerously competent and hilariously inept, whichever is most convenient at the moment. “They have a database of menstrual data, they can use data science and pattern analysis to detect changes in a woman’s reproductive cycle and use that information to make decisions to harm her!” minutes later App developers are rock chewing morons, there’s no way they could detect a pattern of strange data entering their database all at once, figure out what it is possibly by googling the name of their app and finding a Tumblr post about polluting the app, and then cancel those suspicious accounts."
I agree with the first half… It’s very easy to ingest and sift through insane amounts of data
What isn’t easy is doing so usefully. Yes, if you can link the account to a person, it’s trivial to pull up their records. Linking is easier said than done - it’s doable, but to make it scale you have to get the full records of device IDs, link them back to a number, then link them to a person. Minimum, you’d need the telco’s data
That’s a staggering amount of work - it’s much easier to do it if the app also has phone numbers, but even then where do you link it? The telco’s have an account holder (which often will be a family member), 50 separate dmvs might have more accurate links, but they’re largely legacy systems that will be a nightmare to work with. It’s doable, but it’s hard
Then you get to distribute this super extensive database of personal information - at this point it’s prism, and probably already has most of this data - they’d just have to ingest period data too
But we don’t give that kind of access to local police, because then every government would end up with it. And that’s a big and genuine security threat… But also a very unwieldy thing to work with. More data means more man hours to work with
The other direction is far more practical - if you start by looking at the data, you can tie it back to a person if they match a pattern. Then you can look at just the records you do have, and pay Amazon or the credit agencies for more. A human can easily investigate another human, because we are great with unstructured data, and computers aren’t
A chaotic data source means more bad leads to manually chase down. Man hours are limited, and people have morale - if a cop wastes an hour on a lead that ends with a spare phone or a single man, they’re going to complain and drag their feet. If productivity and morale are in the garbage, that’s going to lead to pushback. If it happens enough, the message at the top will be “this program doesn’t work”
It would be far better to find the patterns and target them methodically, but even chaotic garbage is effective - data analysis isn’t easy to automate, it’s very expensive to do when accuracy matters and they’re poisoning the data source
We’d need to identify some threat model to continue the discussion. I don’t know what people are afraid of. I’d say the other way round is more likely. For example a state decides to pursue people terminating a pregnancy. They can use data from telecommunications providers to find out which phones cross the border to the neighboring state and return the same or the next day. Disregard people who do it regularly, and then correlate that data to other factors. Like pull up the menstrual tracker account that was accessed by that specific IP address.
We know since Snowden that some agencies do similar things (supposedly for terrorism) and generally a lot of logs are kept. Also we have lots of automatic license plate readers and additional surveillance available.
Aside from that, it is spread that Amazon knows if you’re pregnant before you do. They could also buy the data who is interested in romper suits, supplements or other specific things and then isn’t. I suppose it’s not exactly about that… More that Amazon have some good heuristics and algorithms to predict things from general shopping behaviour. And you could also do the same thing to menstrual tracking. The cycle is pretty regular. And then it usually stops once someone gets pregnant. And I believe after that it takes some time to settle down to a very regular pattern again. You could easily detect that with an algorithm. And simultaneously get rid of artificial (spammed) data that doesn’t follow what is possible. Probably takes a skilled programmer like 3 weeks and then you can tell if an account owner is real, and probably even if they take some contraceptive or not, due to the slight variations. And if an app has some recommendations features, they’re likely to already include the groundworks for data analyzing.
Ultimately, the government already analyzes and stores the data from telco providers. And it’s always easier to combine several factors to make good predictions, than to rely on a single source. And I’d say this kind of surveillance has to be done automatically, anyways. It’s almost never feasible to sift through databases manually.
Ok, let’s use your first example. Someone crosses into a neighboring state and returns in the same day…I had co-workers who did that every day.
Let’s narrow that down… You cross into another state with abortion care once and return in the same day. Or maybe you’re a salesman closing a deal. Or maybe you’re visiting family and have work tomorrow… And honestly, both those situations are far more frequent. That happens every day. It happens more if you live near the border - otherwise you probably got a hotel. Unless you can’t afford a hotel. And the list goes on - all this structured data turns into stories at some point
Here’s the thing. Prism could handle it, because it’s a ton of people on the payroll
The government is not a monolith though…9/11 is a great example. We knew it would happen, we knew it was planned, but the right people didn’t know in the right time, because the agencies are not a monolith.
Because that is the hard part - communication is hard, harder with security concerns. More data means more analysts reviewing it - you can collect all the data you could want , (and we do), you could hire all the analysts you can afford (and we do), but that still gives you severe limits
We’re actually pretty great at stopping terrorism, but we do that (in part) because we have all this data and use it for specific ends
None of this shit is easy - I used to do this, specifically. How do you take 15 data sources that sometimes conflict, and deconflict them? There’s no hierarchy of truth here. This is literally a cutting edge problem - it’s a literal holy Grail. No one can solve it in 3 weeks, or even 3 years
You want a 20% rate? I could give it to you tomorrow, poisoned data or no, I could give it to you in weeks… Maybe not 3, because that’s a shit ton of data sources, but with proper motivation I could pump it out.
You want 90%? Give me a century or two, and I’m good at this. Maybe a genius could give it to you in a lifetime of with
It’s like they say in game dev, you can do 90% in 10% of the time, but the last 10% takes 90% of the time. And that’s a solved problem.
Except this is an unsolved problem, possibly the most lucrative unsolved problems in history
I think that’s overestimating the complexity. In my example you can just delete all data from people who cross the border regularly. I heard like >80% of Americans don’t travel that much. So you’d still catch the vast majority. And there are additional giveaways. Visiting relatives will follow a pattern or coincide with holidays like every other thanksgiving. Weekend trips will start at the end of a week while work will be during the week and often someone would visit a worksite multiple times.
And correlating data and having multiple datapoints helps immensely. For example if you want to correlate license plates with cell tower data: One measurement will only narrow it down to a few hundreds or thousands of people who passed the highway at that point. But, a single additional datapoint will immediately give an exact answer. Because it’s very unlikely that multiple of the people also return at the same time. Same applies to other statistics.
And you don’t even need to figure out the patterns. It’s a classification problem. And that’s a well understood problem in machine learning. You need a labeled dataset with examples and ML will figure out the rest. No matter if it’s deciphering hand writing, figuring out shopping behaviour to advertise, or something like this. We figured out the maths a long time ago. Nowadays it’s in the textbooks and online courses and you just need some pre-existing data to start with. Maybe you’re right and compiling a dataset will take more than 3 weeks. But it’s certainly doable and not that complicated. And menstrual cycles follow patterns. That makes machine learning a precise approach. It’ll home in on the ~4weeks cycle, find outliers and data that never followed a realistic cycle.
I agree, there are complications. People need to be incentivised to pay attention. Government agencies regularly fail at complex tasks. Due to various reasons. But it’s probably enough to make peoples’ lives miserable if they have to live in constant fear. So there is an additional psychological factor, even if they don’t succed with total surveillance.
And this approach is a bit unlikely anyways. It’s far easier to pass a law to force clinics to rat out people or something like that.
But my guess is that [predictive policing](https://en.wikipedia.org/wiki/Predictive_policing might become an issue. Currently we seem to stick to intelligence agencies and advertising with that technology (and Black mirror episodes and China). But that’s mainly a political choice.