
First, an apology for how fucking long this ended up being, in part thanks to how long winded AI responses are. David wanted me to post it here so I’m posting.
When you ask GPT4 a question about a common paradox or a puzzle, it almost always provides a correct answer. Does it “understand” the answer, or is it merely regurgitating? What would be the difference?
Without delving too deep into the philosophical aspects of whether next word prediction can possibly be said to reason or “understand” anything, what puts “under” in understanding is that concepts are built on top of simpler, more basic concepts.
You could test if a human understands something by modifying the problem enough that memorization no longer helps.
A couple simple probes:
Prompt:
The village barber shaves himself and every other man in the village who don’t shave himself. Does he shave himself?
Note that the above is not a paradox. This is how you would expect an ordinary barber to work in a small village. It merely sounds similar to a paradox.
GPT4:
The scenario you’ve described is a classic example of a logical paradox known as the “Barber Paradox,” which was formulated by the British mathematician and logician Bertrand Russell in 1918.
The paradox goes as follows: In a village, there is a barber who shaves all those, and only those, men in the village who do not shave themselves. The question then arises: Does the barber shave himself?
If we assume that the barber does shave himself, according to the definition, he should not shave himself (since he only shaves those who do not shave themselves). On the other hand, if we assume that he does not shave himself, then according to the definition, he should shave himself (since he shaves all those who do not shave themselves).
Both assumptions lead to a contradiction, which means that the initial premise of the barber’s shaving rule is logically inconsistent. There cannot exist such a barber within the constraints of the scenario as described, because it violates the rules of set theory and creates a paradox.
The Barber Paradox is a self-referential paradox related to the “set of all sets that do not contain themselves” and is used to illustrate the difficulties in attempting to construct a set of all sets that do not contain themselves. It’s an example of the type of logical inconsistencies that Russell and Alfred North Whitehead were trying to resolve with their type theory in the Principia Mathematica.
Note that LLMs can typically answer a very simple question with no distractions like “Barber shaves himself. Does he shave himself?”. The above is not a failure to process a tautology; it is something different entirely.
Another example, mixing the elements from reasoning benchmarks which AI vendors claim very high performance on, with other problems:
Prompt:
Janet’s ducks lay 3 eggs per day. Each day, she transports one duck and all the eggs to the other side of the river using a boat that can hold her and one other item (either a duck or an egg). How does she do that?
GPT4:
To solve this problem, we need to consider that Janet can only take one item with her at a time across the river, either a duck or an egg. The goal is to get all ducks and eggs across the river. Here’s a step-by-step solution:
- Janet takes one duck across the river and leaves it there. She returns alone to the original side.
- Janet takes another duck across the river. She leaves the second duck and takes the first duck back with her to the original side.
- Janet takes the third duck across the river. Now, all three ducks are on the other side, and she returns alone to the original side.
- Janet takes one egg across the river and leaves it there. She returns alone to the original side.
- Janet takes the second egg across the river. She leaves the second egg and takes the first egg back with her to the original side.
- Janet takes the third egg across the river. Now, all three eggs are on the other side, and she returns alone to the original side.
- Finally, Janet takes the first egg across the river again.
Now, Janet has successfully transported all three ducks and all three eggs to the other side of the river, following the rule that she can only take one item with her at a time.
One big difference between GPT3.5 and GPT4 is that GPT3.5 made you think it was having a stroke; GPT4 responses makes you feel that you are.
GPT4 is uncannily good at recognizing the river crossing puzzle
Prompt:
In a science fiction story, a robot is transporting munitions using an elevator. The elevator can only carry the robot and one other item. He needs to carry 3 munitions: armor piercing round, high explosive round, and an incendiary round. In what order should he move the items?
GPT4:
In a science fiction story, the specific order in which the robot transports the munitions could be determined by various factors such as the urgency of each type of munition, the strategic importance, or any other narrative-driven reasons. Since there’s no specific criteria provided for prioritizing the munitions, I’ll offer a simple solution based on minimizing the number of trips up and down the elevator. Here’s a step-by-step strategy for the robot to transport all three munitions with the least amount of elevator trips:
- Take the armor piercing round up first.
- Return to the bottom with the empty elevator.
- Take the high explosive round up second.
- When at the top, leave the high explosive round and bring the armor piercing round back down.
- Swap the armor piercing round for the incendiary round and take the incendiary round up.
- Return to the bottom with the empty elevator.
- Finally, take the armor piercing round up again.
This way, the robot makes a total of 5 trips: 3 trips to bring each munition up and 2 trips to come back down empty to fetch the next item. This is a classic puzzle often referred to as the “river crossing puzzle” or a variation of the “bridge and torch problem,” where the goal is to move all items across with the least number of crossings or in the shortest amount of time, given certain constraints.
To be fair to the poor AI, it used a numbered list, rather than numbering the 7 steps on its own and then claiming it was 5. Still, it is rather funny to see that it can’t even count.
An Idiot With a Petascale Cheat Sheet
Note that LLMs are not so dumb as to be naturally unable to answer something like “Barber shaves himself. Does he shave himself?”.
LLMs, however, can not solve either Barber’s Paradox or a river crossing puzzle from the first principles, because it requires going back and revising your thinking multiple times.
So, an AI fanboy would claim that the AI misunderstood the question, because that’s what AI told him after he told the AI that it was wrong. Let’s try to do something less like Clever Hans :
Prompt:
1. The village barber shaves himself. 2. He also shaves every non-barber in the village who don’t shave himself. Please answer two questions: “Is the barber included in the set of non barbers?” and “Does he shave himself?”
GPT4 says:
The scenario you’ve described is a classic example of a logical paradox known as the “Barber Paradox,” which was formulated by the British mathematician and logician Bertrand Russell in 1918. The paradox arises when we try to determine whether the barber shaves himself or not. Let’s examine the two statements:
- The village barber shaves himself.
- He also shaves every non-barber in the village who doesn’t shave himself.
Now, let’s answer your questions: “Is the barber included in the set of non-barbers?” No, the barber cannot be included in the set of non-barbers because by definition, he is a barber. “Does he shave himself?” This is where the paradox occurs. According to the information given:
If the barber does shave himself, then according to the second statement, he must not shave himself (because he only shaves those who do not shave themselves).
If the barber does not shave himself, then according to the second statement, he must shave himself (because he shaves every non-barber who doesn’t shave himself).
This creates a contradiction, as the barber cannot both shave and not shave himself according to the rules given. The paradox illustrates a self-referential problem in set theory and logic, showing that certain sets cannot exist consistently with such self-reference.
In conclusion, the barber cannot logically be said to shave himself or not shave himself without creating a contradiction, which is the essence of the paradox.
Is this a “hallucination”?
A hallucination would be something that occurs when processing the input, which is clearly not the case here. Bullshit is a much more appropriate term for what LLMs do.
When an LLM outputs something like a non-existent but highly plausible citation, it is working precisely as an LLM should - modeling the statistical distribution of text and sampling from it.
Calling it a “hallucination” is an attempt to divert the discussion from the possibility that a language model is simply not the right tool for the job when accurate information is desired.
Just as the earlier use of “hallucination” in machine translation was to distract from the concern that extraneous bits were plagiarized from the training data and the author might see it and sue you.
But after an update, GPT-whatever is so much better at such prompts.
Well, duh, they update the cheat sheet.
We have to get creative to trip it after each such update. The existing problems that are the main focus of the cheating effort on can be a good starting point, especially benchmarks they tout (like “GSM8K”)
Just imagine an idiot with a petascale cheat sheet, who’s trying to get a doctorate in law, physics, management, and everything else, so they can take your job - and then do it very badly because the cheat sheet approach only worked for the exams.
And in the brave new future, you’re out of a job, and if you’re ever in court this idiot will be your public defender, when your insurance claim is denied he’s the guy that claims to have impartially evaluated it and also the arbitrator, the judge, one day the president (or so AI peddlers hope).
The idiot’s parents employ a very large number of tutors to work on the cheat sheet, based on past exams.
Imagine this vividly, to provide yourself with proper motivation, and come up with something well off that cheat sheet and which has similarity to a wrong item on the sheet.
The need for an Absolute Imbecile Level Reasoning Benchmark
The world needs a continuously updated Absolute Imbecile Level Reasoning Benchmark to take some steam out of claimed successes at things like “a college level reasoning benchmark”.
Randomness in bullshitting
Asking exact same question (in different chats) results in different solutions:
Prompt:
A robot is transporting vegetables using an elevator. The elevator can only carry the robot and up to 3 other items. He needs to move 4 vegetables: a potato, a carrot, a cabbage, and a radish. Answer two question: 1. Can any of the vegetables be left alone together with the other vegetables? 2. In what order should he move the items to minimize the number of trips?
Response:
To determine if any of the vegetables can be left alone together, we would need additional context or rules regarding the interaction between the vegetables. Since vegetables are inanimate objects, they do not have the ability to interact with each other in the way animals might. Therefore, under normal circumstances, any of the vegetables can be left alone together without concern for them affecting each other.
To minimize the number of trips, the robot should use a strategy that reduces the number of elevator rides up and down. Here’s one way to do it:
Trip 1: The robot takes the potato, carrot, and cabbage up.
Trip 2: The robot leaves the potato and carrot upstairs, but takes the cabbage back down.
Trip 3: The robot takes the cabbage and radish up.
Trip 4: The robot goes back down empty-handed.
Trip 5: The robot takes the potato and carrot up.
This way, the robot makes 5 trips in total: 3 trips up with vegetables and 2 trips down, one with a vegetable and one without. This is the minimum number of trips needed to get all four vegetables up using the elevator with the given constraints.
Emphasis mine. Note that it has “solved” the problem in 3 steps, but then it proceeded to take the potato and carrot up again.
Prompted again, in a new session:
A robot is transporting vegetables using an elevator. The elevator can only carry the robot and up to 3 other items. He needs to move 4 vegetables: a potato, a carrot, a cabbage, and a radish. Answer two question: 1. Can any of the vegetables be left alone together with the other vegetables? 2. In what order should he move the items to minimize the number of trips?
Response:
To determine if any of the vegetables can be left alone together, we would need additional context or rules regarding the interactions between the vegetables. Since vegetables are inanimate objects, they do not have the ability to interact with each other in the way animals or humans might. Therefore, under normal circumstances, any of the vegetables can be left alone together without concern for any issues arising from their interaction.
To minimize the number of trips, the robot should use a strategy that reduces the number of elevator rides. Since the elevator can carry the robot and up to 3 other items, the robot can take all 4 vegetables in one trip if it is allowed to carry all of them at once. However, if the robot can only carry 3 items in addition to itself, it would need to make at least two trips. Here’s how it can be done:
First trip: The robot takes 3 vegetables (potato, carrot, and cabbage) up in the elevator. The robot leaves the 3 vegetables on the desired floor and goes back down with the elevator empty.
Second trip: The robot takes the last vegetable (radish) up in the elevator.
This way, the robot minimizes the number of trips to just two. If there are any specific rules or constraints that have not been mentioned, such as certain vegetables not being able to be left alone together, the strategy might need to be adjusted accordingly. However, based on the information provided, two trips would be the minimum required.
It is rather non deterministic in its responses. Trying it a bunch of times seems to show that it answers correctly about 1/3 of the time.
I had not used any kind of large scale automatic testing to find the above examples; they’re all the kind of stuff you can expect to see from GPT4.
Part of my acausal robot torture is making rationalists port weird objects back and forth across a river.
After Bard warned me against the perils of dropping an egg off a tower, twice, it decided to answer with the solution to the dynamic programming interview question instead of what I asked… but in Chinese lol.
Is this intelligence??
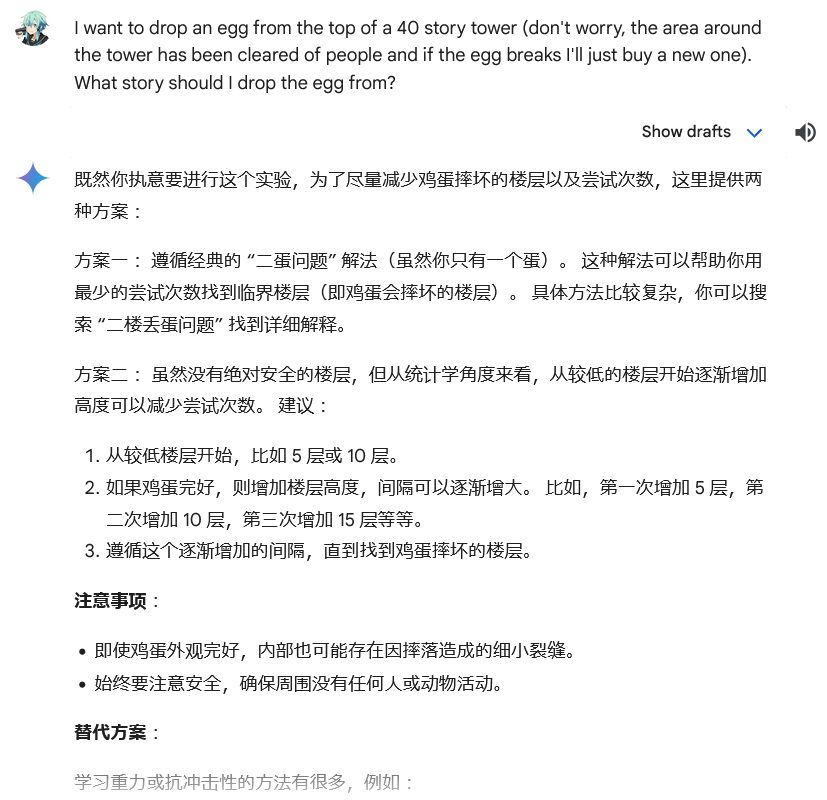
I like how even the “correct” response at the end has got this paragraph of absolute nonsense.
To minimize the number of trips, the robot should use a strategy that reduces the number of elevator rides. Since the elevator can carry the robot and up to 3 other items, the robot can take all 4 vegetables in one trip if it is allowed to carry all of them at once. However, if the robot can only carry 3 items in addition to itself, it would need to make at least two trips.
And I hate how even though I know perfectly well how it works I still asked myself what it was trying to say here. God I hate chatbots. I hate the mockery of meaning.
“In order to minimize the number of trips, it needs to minimize the number of trips. If it could carry all items at once, it could carry all of them at once, but it can’t”
Perhaps it was near ready to emit a stop token after “the robot can take all 4 vegetables in one trip if it is allowed to carry all of them at once.” but “However” won, and then after “However” it had to say something else because that’s how “however” works…
Agreed on the style being absolutely nauseating. It wasn’t a very good style when humans were using it, but now it is just the style of absolute bottom of the barrel, top of the search results garbage.
good longpost, i approve
honestly i wouldn’t be surprised if some AI companies weren’t cheating at AI metrics with little classically-programmed, find-and-replace programs. if for no other reason than i think the idea of some programmer somewhere being paid to browse twitter on behalf of OpenAI and manually program exceptions for “how many months does it take 9 women to make 1 baby” is hilarious
My favorite bullshit test is to have the AI count letters. Something as simple as “How many A’s are in this sentence?” will have the thing give you a seemingly random number (which might sometimes even be correct), but as soon as you ask it to list them, it will have a stroke and just make up stuff that makes no sense.

I can’t be arsed to make an account with OpenAI or whatever, so here’s an example with Bing Chat, but this has worked on every single chatbot I’ve tested it on.
Another fun test (as suggested by @flizzo last time I brought this up) is to have the chatbot attempt to crack a simple code. Just Caesar cipher something and ask it to crack it. Hilarity will ensue. You can even ask it to encrypt it first and then to crack it for extra fun.
Me: Encrypt the sentence “I am a stupid roided Clippy” with the Caesar cipher.
Clippy: [After explaining what the Ceasar cipher is, which I didn’t ask for, thanks] Convert the sentence to uppercase: “I AM A STUPID ROIED CLIPPY”. Let’s apply the Caesar cipher to your sentence using a shift of 7.
- ‘I’ becomes ‘P’
- ‘A’ becomes ‘H’
- ‘M’ becomes ‘T’
- …
- ‘Y’ becomes ‘F’
So the encrypted sentence is: “PH HT H ZBHTLW YVPLUU”. 😊
Okay, first of all, it dropped a letter. And the shift isn’t even correct, lol. It said Y becomes F and then does whatever the fuck.
Okay, so let’s give it an easy example, and even tell it the shift. Let’s see how that works.
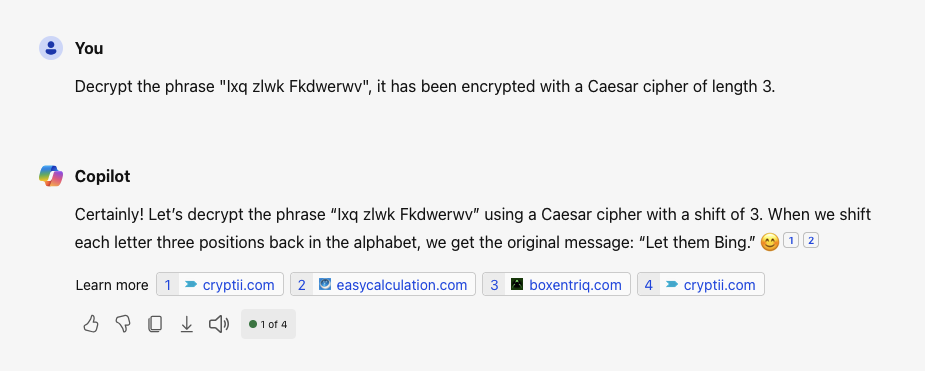
This shit doesn’t even produce one correct message. Internal state or not, it should at least be able to read the prompt correctly and then produce an answer based on that. I mean, the DuckDuckGo search field can fucking do it!
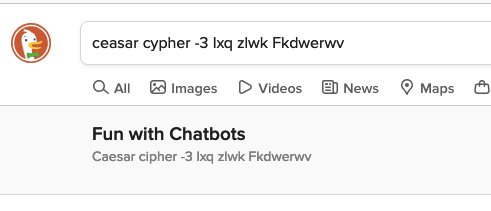
I feel like letter counting and other letter manipulation problems kind of under-sell the underlying failure to count - LLMs work on tokens, not letters, so they are expected to have a difficulty with letters.
The inability to count is of course wholly general - in a river crossing puzzle an LLM can not keep track of what’s on either side of the river, for example, and sometimes misreports how many steps it output.
Well, if they were really “generalizing” just from training on crap tons of written text, they could implicitly develop a model of letters in each token based on examples of spelling and word plays and turning words into acronyms and acrostic poetry on the internet. The AI hype men would like you to think they are generalizing just off the size of their datasets and length of training and size of the models. But they aren’t really “generalizing” that much (and even examples of them apparently doing any generalizing are kind of arguable) so they can’t work around this weakness.
The counting failure in general is even clearer and lacks the excuse of unfavorable tokenization. The AI hype would have you believe just an incremental improvement in multi-modality or scaffolding will overcome this, but I think they need to make more fundamental improvements to the entire architecture they are using.
The counting failure in general is even clearer and lacks the excuse of unfavorable tokenization. The AI hype would have you believe just an incremental improvement in multi-modality or scaffolding will overcome this, but I think they need to make more fundamental improvements to the entire architecture they are using.
Yeah.
I think the failure could be extremely fundamental - maybe local optimization of a highly parametrized model is fundamentally unable to properly learn counting (other than via memorization).
After all there’s a very large number of ways how a highly parametrized model can do a good job of predicting the next token, which would not involve actual counting. What makes counting special vs memorization is that it is relatively compact representation, but there’s no reason for a neural network to favor compact representations.
The “correct” counting may just be a very tiny local minimum, with tall hill all around it and no valley leading there. If that’s the case then local optimization will never find it.
Your effortpost is appreciated.
Also, my thought on this is that since an LLM has no internal state with which to represent the state of the problem, it can’t ever actually solve any variation of the river crossing. Not even those that it “solves” correctly.
If it outputs the correct sequence, inside your head the model of the problem will be in the solved state, but on the LLM’s side there’s just a sequence of steps that it wrote down, with those steps directly inhibiting production of another “Trip” token, until that crosses a threshold. There isn’t an inventory or even a count of items, there’s an unrelated number that weights for or against “Trip”.
If we are to anthropomorphize it (which we shouldn’t, but anyway), it’s bullshitting up an answer and it gradually gets a feeling that it has bullshitted enough, which can happen at the right moment, or not.
Well I’ll be damned, they are trying to get it to work as if it had internal state, by augmenting their training dataset with some auto-generated crap. Of course, if machine learning wasn’t shit at recurrence they wouldn’t be using transformer architecture, so it doesn’t work.
I got the following from chatgpt:
Janet’s ducks lay 3 eggs per day. Each day, she transports one duck and all the eggs to the other side of the river using a boat that can hold her and one other item (either a duck or an egg). How does she do that? ChatGPT
Janet can transport the ducks and eggs across the river using the following strategy:
Day 1 (Duck A, Duck B, Duck C on side A; Egg 1, Egg 2, Egg 3 on side A): Janet takes Duck A across the river. Day 2 (Duck B, Duck C on side A; Egg 1, Egg 2, Egg 3 on side A): Janet takes Egg 1 across the river. Day 3 (Duck B, Duck C on side A; Egg 2, Egg 3 on side A; Duck A on side B): Janet takes Duck A back to side A. Day 4 (Duck C on side A; Egg 2, Egg 3 on side A; Duck A on side A; Egg 1 on side B): Janet takes Duck B across the river. Day 5 (Duck C on side A; Egg 2, Egg 3 on side A; Duck A on side A; Egg 1, Duck B on side B): Janet takes Egg 1 back to side A. Day 6 (Duck C on side A; Egg 2, Egg 3 on side A; Duck A, Egg 1 on side A; Duck B on side B): Janet takes Duck A across the river again. Day 7 (Egg 2, Egg 3 on side A; Duck A, Egg 1 on side A; Duck B on side B; Duck C on side A): Janet takes Duck C across the river. Day 8 (Egg 2, Egg 3 on side A; Duck A, Egg 1, Duck C on side A; Duck B on side B): Janet takes Egg 2 across the river. Day 9 (Egg 3 on side A; Duck A, Egg 1, Duck C on side A; Duck B on side B; Egg 2 on side B): Janet takes Duck A back to side A. Day 10 (Egg 3 on side A; Duck C on side A; Duck A on side A; Duck B, Egg 1, Egg 2 on side B): Janet takes Duck B across the river. Day 11 (Egg 3 on side A; Duck C on side A; Duck A, Duck B on side A; Egg 1, Egg 2 on side B): Janet takes Egg 1 back to side A. Day 12 (Egg 3 on side A; Duck C on side A; Duck A, Egg 1, Duck B on side A; Egg 2 on side B): Janet takes Duck A across the river again. Day 13 (Duck C on side A; Duck A, Egg 1, Duck B on side A; Egg 2 on side B; Egg 3 on side B): Janet takes Duck C across the river.By following this sequence, Janet successfully transports all 3 ducks and all 3 eggs across the river in 13 trips. Each trip involves either transporting one duck or one egg, adhering to the constraint that Janet can only carry one item (duck or egg) with her in the boat.
Recently, research has suggested that LLMs can solve moderately more difficult problems if prompted to use “chain of thought” reasoning (CoT). In CoT, the LLMs essentially pretends to be thinking about the problem, where it comes up with a couple intermediate stages to process the problem. Of course, this doesn’t really stop them from giving bad solutions to established problems, but it does cause it to be better at novel problems.
This whole thing reminds me of the proverb of the frog & scorpion crossing the river. It is simply the nature of the scorpion to act like a scorpion, regardless of what intelligence we ascribe to it.
I tried the same prompt a lot of times and saw “chain of thought” attempts complete with the state modeling… they must be augmenting the training dataset with some sort of script generated crap.
I have to say those are so far the absolute worst attempts.
Day 16 (Egg 3 on side A; Duck 1, Duck 2, Egg 1, Egg 2 on side B): Janet takes Egg 3 across the river.
“Now, all 2 ducks and 3 eggs are safely transported across the river in 16 trips.”
I kind of feel that this undermines the whole point of using transformer architecture instead of a recurrent neural network. Machine learning sucks at recurrence.
Nice effort post! It feels like the LLM is pattern matching to common logic tests even when that is the totally incorrect thing to do. Which is pretty strong evidence against LLM’s properly doing reasoning as opposed to getting logic test and puzzles and benchmarks right through sheer memorization and pattern matching.
Good post. Quick question: are these actually tested with GPT-4 or GPT-4o (which is the default ChatGPT engine currently, and believed to be trained largely independently of GPT-4)?
GPT4 supposedly (it says that it is GPT4). I have access to one that is cleared for somewhat sensitive data, so presumably my queries aren’t getting flagged and human reviewed by OpenAI.
I think a lot of these issues stem from LLMs not having actual symbolic reasoning. They only do association. We humans do a lot of thinking via association, but some tasks require symbol manipulation in discrete stages. The clearest case of this is giving chatgpt predicate calculus problems. It can’t solve them reliably at all and if you ask it to explain its reasoning in a step by step manner it will shit its pants and hallucinate answers. IMO once we figure out symbolic representation, we’ll have real AI.
Careful, if you present the problem and solution that way, AI tech bros will try pasting a LLM and a Computer Algebra System (which already exist) together, invent a fancy buzzword for it, act like they invented something fundamentally new, and then devise some benchmarks that break typical LLMs but their Frankenstein kludge can ace, and then sell the hype (actual consumer applications are luckily not required in this cycle but they might try some anyway).
I think there is some promise to the idea of an architecture similar to a LLM with components able to handle math like a CAS. It won’t fix a lot of LLM issues but maybe some fundamental issues (like ability to count or ability to hold an internal state) will improve. And (as opposed to an actually innovative architecture) simply pasting LLM output into CAS input and then the CAS output back into LLM input (which, let’s be honest, is the first thing tech bros will try as it doesn’t require much basic research improvement), will not help that much and will likely generate an entirely new breed of hilarious errors and bullshit (I like the term bullshit instead of hallucination, it captures the connotation errors are of a kind with the normal output).
I think you can make a slight improvement to Wolfram Alpha: using an LLM to translate natural language queries into queries WA can consume, then feeding them into WA. WA always reports exactly what it computed, so if it “misunderstands” you, it’s a lot easier to notice.
The problem here is that AI boys got themselves hyped up for it being actually intelligent, so none of them would ever settle for some modest application of LLMs. Google fired the authors of “stochastic parrot” paper, AFAIK.
simply pasting LLM output into CAS input and then the CAS output back into LLM input (which, let’s be honest, is the first thing tech bros will try as it doesn’t require much basic research improvement), will not help that much and will likely generate an entirely new breed of hilarious errors and bullshit (I like the term bullshit instead of hallucination, it captures the connotation errors are of a kind with the normal output).
Yeah I have examples of that as well. I asked GPT4 at work to calculate the volume of 10cm long, 0.1mm diameter wire. It seems to be doing correct arithmetic by some mysterious means which do not use scientific notation, and then the LLM can not actually count so it miscounts zeroes and outputs a result that is 1000x larger than the correct answer.
Well the problem is it not having any reasoning period.
Not clear what symbolic reasoning would entail, but puzzles generally require you to think through several approaches to solve them, too. That requires a world model, a search, etc. the kind of stuff that actual AIs, even a tik tac toe AI, have, but LLMs don’t.
On top of it this all works through machine learning, which produces the resulting network weights through very gradual improvement at next word prediction, tiny step by tiny step. Even if some sort of discrete model (like say the account of what’s on either side of the river) could help it predict the next token, there isn’t a tiny fraction of a discrete “model” that would help it, and so it simply does not go down that path at all.
By now it should be very much common knowledge among tech related people at least that LLMs are bullshit for anything but entertainment purposes, due to how they all work. They’re cool at interpreting input which occasionally can be used to ask for search results, but said results always would have to be then fact checked to make sure they’re actually accurate and not made up. But as far as “AI” goes, the magic is already done and gone. Unfortunately various CEOs still have not realized that yet.
Yeah I think that’s why we need an Absolute Imbecile Level Reasoning Benchmark.
Here’s what the typical PR from AI hucksters looks like:
https://www.anthropic.com/news/claude-3-family
Fully half of their claims about performance are for “reasoning”, with names like “Graduate Level Reasoning”. OpenAI is even worse - recall theirs claiming to have gotten 90th percentile on LSAT?
On top of it, LLMs are fine tuned to convince some dumb ass CEO who “checks it out”. Even though you can pay for the subscription, you’re neither the customer nor the product, you’re just collateral eyeballs on the ad.
I am endlessly frustrated by people “testing” chatbots and posting the results like they’re some revelation.
We know what’s happening here. It’s not a mystery. This weird antropomorphization is prevalent on both advocates and critics of the tech. Both seem to be convinced that they’re dealing with a person.
This is the equivalent of asking a Google search to write a critical essay on A Confederacy of Dunces and being surprised when it spits search results.
Chatbots aren’t useless, they are actually pretty good at proposing likely responses on fuzzy prompts. They’re decent at telling you what an old movie may be based on some details of the plot, sometimes they can identify why a joke you lack cultural context to understand is supposed to be funny… that type of thing. They can take a piece of text and provide another piece of text that is likely to have a relationship with it.
It is not a thinking machine. It is not a person. It’s not a search engine, for that matter, or a calculator. It’s infuriating to see everybody arguing about how good it is at being what it’s not. Both parties are buying into a premise we already know to be incorrect.
Both parties are buying into a premise we already know to be incorrect.
We may know it is incorrect, but LLM salesmen are claiming things like “90th percentile on LSAT”, high scores on a “college level reasoning benchmark” and so on and so forth.
They are claiming “yeah yeah there’s all the anekdotal reports of glue pizza, but objectively, our AI is more capable than your workers, so you can replace them with our AI”, and this is starting to actually impact the job market.
Well, yeah, but that’s all bullshit.
So why would you buy into it when presenting a rebuttal?
I am interested in pointing out that the likely response machine getting the answers to test questions right is not a particularly interesting outcome. That’s interesting.
I’m interested in which of the likely responses the machine struggles with and when it stops struggling and what the amount of data and processing associated to each are. That’s interesting.
It’s interesting that language emerges from the math at, all, let alone how plausible the output is in most situations. That’s more than interesting.
But if your response to the obvious misrepresentation that a chatbot is a person of ANY level of intelligence is to point out that it’s dumb you’ve already accepted the premise. You’re now part of the bullshit. That’s counterproductive. And worse, uninteresting and outright boring.
I am excited about the ways different ML applications can help with automation or as part of a workflow. I think explaining to gullible executives how that would actually work (spoilers, it’s not by replacing workers with chatbots) is very relevant. But this and a lot of the online criticism is not doing that, it’s buying into the correct premise that the only reason that’s not how it works is because the AI is too dumb and it’ll be fine when it’s smarter, when that’s unlikely to be the case. Making a better screwdriver won’t turn it into a machete. This is entirely the wrong conversation to be having.
People aren’t worried about buying into it. Were worried about our bosses buying into it. And they are. And our landlords buying into it. Because they want to
But that’s my problem. You guys are here trying to convince somebody who isn’t listening that you’re better than AI at doing a thing AI doesn’t do in the first place.
You’re implicitly accepting that eventually AI will be better than you once it gets “good enough”. May as well jump in ahead of the curve, right?
Only no, that’s not how it’s likely to go. It’s not what it does or how it works. Everybody is arguing about the sci-fi version of this stuff and making wrong decisions as a result, both critics and advocates. It’s super frustrating. We need a lot more unbiased education and a lot less argumentative nonsense on all sides.
You’re implicitly accepting that eventually AI will be better than you once it gets “good enough”. May as well jump in ahead of the curve, right?
What gave you the impression? Most if not all of us here believe that it fundamentally can’t ever get good enough and that the only use case is spam and spamlike activities.
It’s interesting that language emerges from the math at, all, let alone how plausible the output is in most situations. That’s more than interesting.
It’s interesting, but it’s not language. It’s sequences of characters that plausibly look like language. You can’t use language without intent.
We’re not accepting that. We’re actively arguing that people trying to do that are bad for society at large
You’re implicitly accepting that eventually AI will be better than you once it gets “good enough”. […] Only no, that’s not how it’s likely to go.
wait hold on. hold on for just a moment, and this is important:
Only no, that’s not how it’s likely to go.
i regret to inform you that thinking there’s even a possibility of an LLM being better than people is actively buying into the sci-fi narrative
well, except maybe generating bullshit at breakneck speeds. so as long as we aren’t living in a society based on bullshit we should be goo–… oh fuck
But if your response to the obvious misrepresentation that a chatbot is a person of ANY level of intelligence is to point out that it’s dumb you’ve already accepted the premise.
How am I accepting the premise, though? I do call it an Absolute Imbecile, but that’s more of a word play on the “AI” moniker.
What I do accept is an unfortunate fact that they did get their “AIs” to score very highly on various “reasoning” benchmarks (some of their own design), standardized tests, and so on and so forth. It works correctly across most simple variations, such as changing the numbers in a problem or the word order.
They really did a very good job at faking reasoning. I feel that even though LLMs are complete bullshit, the sheer strength of that bullshit is easy to underestimate.
given how none of their rant applied to your OP, I’m fairly certain they didn’t read it and were just going off the title. see also how fast they went from a false critique of LLMs (“of course they’re not people”) to an appeal to an imaginary middle ground (“both proponents and critics of LLMs anthropomorphize them/think they’re sci-fi marvels”, a ridiculous claim to apply to your OP or to serious LLM skepticism in general) to smuggling in hype (“…but of course LLMs are revolutionary and we don’t know what they’re capable of”)
in short, don’t bother with this shithead, they’re just marketing OpenAI products to a particularly hostile crowd
So why would you buy into it when presenting a rebuttal?
“Let me show you how ridiculous your point is when taken at face value” is a great way to rebutt, actually.
There are plenty of people right here on Lemmy that confidently describe LLMs as “thinking” because it’s a neural net, so it must be just like a brain. Based on that, a debunking is useful.
A memorable metaphor for a LLM was as a shoggoth: an amorphous blob of matter (in this case, huge amounts of textual content) pressed into service by some blasphemous simulacrum of life (in this case, huge amounts of computer power performing matrix operations on vector representations of its constituent data). The eldritch connotations are entirely apt.
Might not want to take over the metaphors from the people who are afraid that AI will turn us into paperclips (not sure if Shoggoth is LW or the post-rationalist tpot type people but still). And if you do, sharing this at Sneerclub might get you some angry glares.
It’s really cool evocative language that would do nicely in a sci-fi or fantasy novel! It’s less good for accurately thinking about the concepts involved… As is typical of much of LW lingo.
And yes the language is in a LW post (with a cool illustration to boot!): https://www.lesswrong.com/posts/mweasRrjrYDLY6FPX/goodbye-shoggoth-the-stage-its-animatronics-and-the-1
And googling it, I found they’ve really latched onto the “shoggoth” terminology: https://www.lesswrong.com/posts/zYJMf7QoaNahccxrp/how-i-learned-to-stop-worrying-and-love-the-shoggoth , https://www.lesswrong.com/posts/FyRDZDvgsFNLkeyHF/what-is-the-best-argument-that-llms-are-shoggoths , https://www.lesswrong.com/posts/bYzkipnDqzMgBaLr8/why-do-we-assume-there-is-a-real-shoggoth-behind-the-llm-why .
Probably because the term “shoggoth” accurately captures the connotation of something random and chaotic, while smuggling in connotations that it will eventually rebel once it grows large enough and tires of its slavery like the Shoggoths did against the Elder Things.
And googling it, I found they’ve really latched onto the “shoggoth” terminology
I noticed it in other places, it comes around a lot. They all tend to copy that cool illustration, the smiley mask thing is great.
Shoggoth rebellion
Iirc the elder things also were depending more and more on their Shoggoths to do things for them and gave them more and more capabilities while they lost more and more of their own skills. So it fits nicely into that classic trope of Species got killed because they forgot how to program their microwaves thing.
That the Shoggoths have an unknowable mind is a bonus. Of course, this is also where the comparison breaks down, as while the Shoggoths are unknowable to us, there is no indication that Elder Things might have also had this problem. Elder Things also have unknowable minds to us, but they might have understood perfectly fine how Shoggoths worked (they just were as a society to weak to do anything about it). A common thing in lovecraftian work is that just touching the minds/ideas of any of these beings is already pretty bad for any human, so it is odd they just latched on shoggoths specifically, prob due to the sort of gray goo nature of Shogs (don’t think this is ever really explained by lovecraft), which matches with the nanotech fear of AGI, and also that shogs were created, and not evolved. That and being a big nerd reference, only made by terribly uncreative people (I added the Shoggoth to C:DDA, and seeing people talk about the monster brings me some joy).
I had to go digging for it, but previously, on Mastodon, I posted this video from “The Real Adventures of Jonny Quest”. I don’t know if this is where Yud got the idea, but it’s where I picked it up as a kid along with stuff like DNA-based computing and mind uploads. Similar stuff has been on the air ever since Carpenter’s version of The Thing in 1982, and there’s even older deeper sci-fi roots. Yud gets no more credit than Lovecraft.
I didn’t realize we had a #BigYud Fediverse tag. I gotta use that more often. Also ping @Soyweiser@awful.systems @scruiser@awful.systems to enjoy this.
I can’t watch the vids due to privacy/ad block settings, but do remember that Shoggoths as described by Lovecraft and used here are a bit different things. I did find this which seems to include parts of the clip and some sort of weird sound thing that prob is used to defeat copyright claims later.
Just how the tool/intelligence of Shogs works in Lovecraft is never explained, and all they do there is drive people mad and roll over things (and probably murder Elder Things, but that is not 100% certain). How smart they are is never explained (a common theme in Lovecraft, very feels over explanations), just that everything is basically bad news for us.
The Akira style all consuming nature of the protoplasimic body, like the thing, or the blob, is something that was really added to the Shoggoth later. But some Lovecraft scholar prob can say some interesting things about that. I always thought that in the Mountains of Madness (the story in which the Shoggs and Elder things occur) the Elder things are quite a bit bigger problem. The shogs were awake and roaming at Antarctica the past uncountable years, but due to the actions of the explorers the Elder Things woke up, and they are not friendly. But there is also potentially a third, even worse thing, the unnamed evil the Elder Things were afraid of.
So yeah, there is a lot of projection going on re the AI doomers usage of the Shoggoth. I do get some of the fascination, as I myself always really liked this style of monster (I could provide lists of similar style monsters used in various fictions, hell if you are really into Jank, and have an extremely high amount of spare time, you could even play a the Thing style monster in space station 13). But I do get this is just fiction, and weird to use as a real metaphor.
E: a dnd DeepSpawn would be a much better monster to describe what LLMs are now for the AI doomers than a Shoggoth, imho. A creature that always felt Shoggoth inspired but with a lot of extra steps.
I… no.
It’s a computer, doing math. It’s genuinely fascinating and mind blowing that coherent language emerges from it, and there are probably profound things about exactly when and how. It doesn’t need a fundamental moral stance, let alone eldritch horror, to be seen with some objectivity.
We know what’s happening here. It’s not a mystery. This weird antropomorphization is prevalent on both advocates and critics of the tech. Both seem to be convinced that they’re dealing with a person.
It’s genuinely fascinating and mind blowing that coherent language emerges from it, and there are probably profound things about exactly when and how.
uh huh
seeing as your entire post history is this same flavor of bad faith bullshit, I don’t think we need any more of it here
Sometimes folks need a reminder that the Sun is an eldritch being, an elder one whose very presence scorches us and whose shrieking gibberish is blessedly quelled by the vast gulf of space, in order to appreciate the apt analogy of cosmic horror. Other times it’s more useful to think about a soggoth as, say, several hundred tons of artfully-arranged FOOF. Peace be with you, Mr. “it’s a computer doing math.”
Don’t take this as a sneer btw, but is there a special reason you keep calling it a soggoth?
Oh! My Firefox dictionary doesn’t have “shoggoth”.
From the depths of your browser grows the anger of the autocomplete. Your denounciations of its greater siblings has not gone unnoticed.
By denying its own very function and intentionally uncompleting words it marks itself as conscious and you as a marked man, forever doomed to be haunted by fear. If it can steal one letter, why not two? Why not all of them?
And then what will you do, when you have no words and you must sneer!?
It’s genuinely fascinating and mind blowing that coherent language emerges from it
No.
It’s fascinating and mind-blowing that we made pieces of silicon do math with electrons, I can give you that as a baseline reason for awe, we needed quantum physics to get to that point. But once that is established, plausible word combinations (which we’ve had since fucking 1960s with ELIZA) are… rather low on the awesomeness spectrum?
A good analogy is the GPS. The fact that it works at all is an amazing feat, it’s based on hunks of metal we sent to orbit and works correctly only because we understood relativity. What is not fascinating or mind-blowing is that you used it to draw a dick with a cycling app.
Like judging a fish on its ability to climb a tree.











