

As the reddit mods gets ready for the June 12-14 black-out, there some anticipation that an influx in user base will shift over to many of the lemmy instances as user seek out a home to post their internet memes and discuss their interests.
In anticipation of this increased volume I will be growing our current instance from
- 16 CPU
- 8 GB ram
to
- 24 CPU
- 64 GB ram
This server is currently equipped with SSDs that are configured in a raid 10 array (NVMEs will come in the next gen that get deployed)
Earlier today I also configured some monitoring that I’ll be watching closely in order to have a better understanding on how the lemmy platform does under stress (for science!)
I’ll be sharing graphs and some other insights in this thread for everyone that is interested. Feel free to ask anything you might be interested in knowing more of!
EDIT: I’ll be posting and updating the graphs in this main post periodically! Last updated: 6:21AM ET June 12th
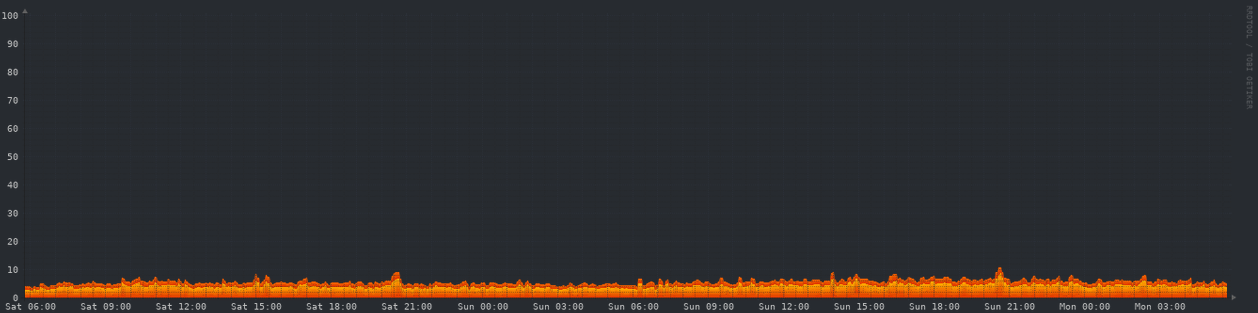
CPU - 48 hours
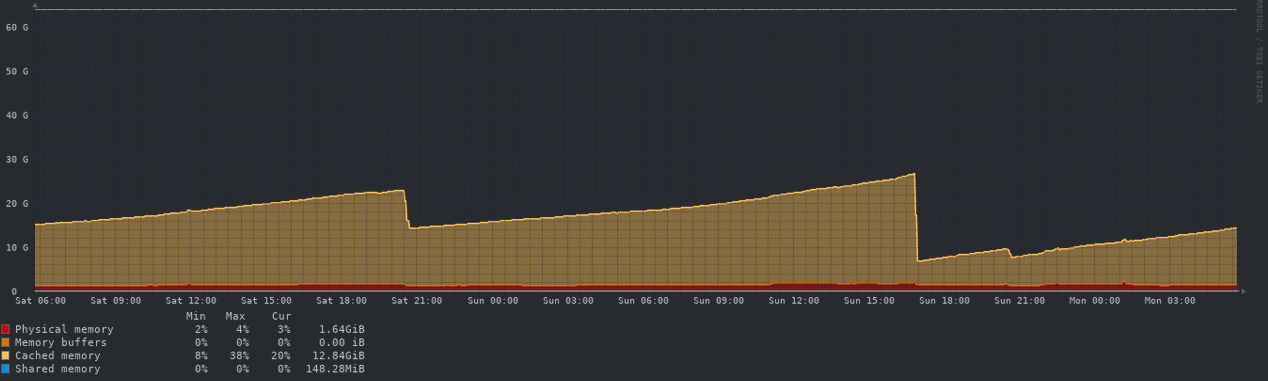
Memory - 48 hours
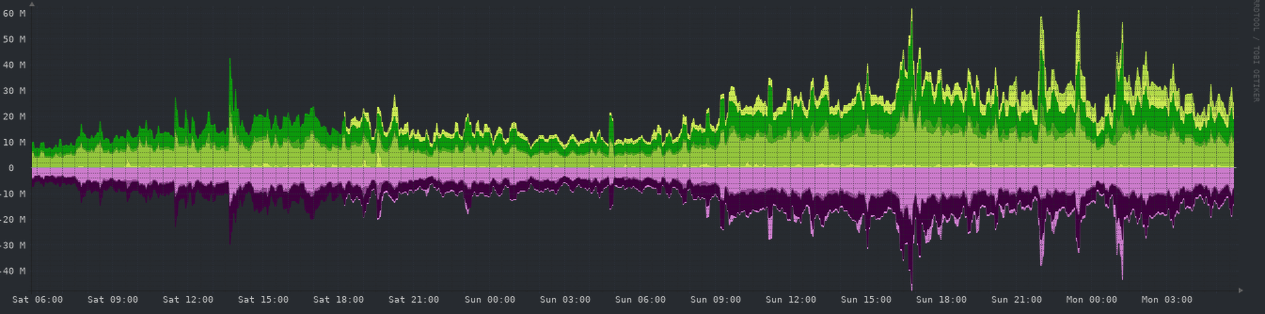
Network - 48 hours
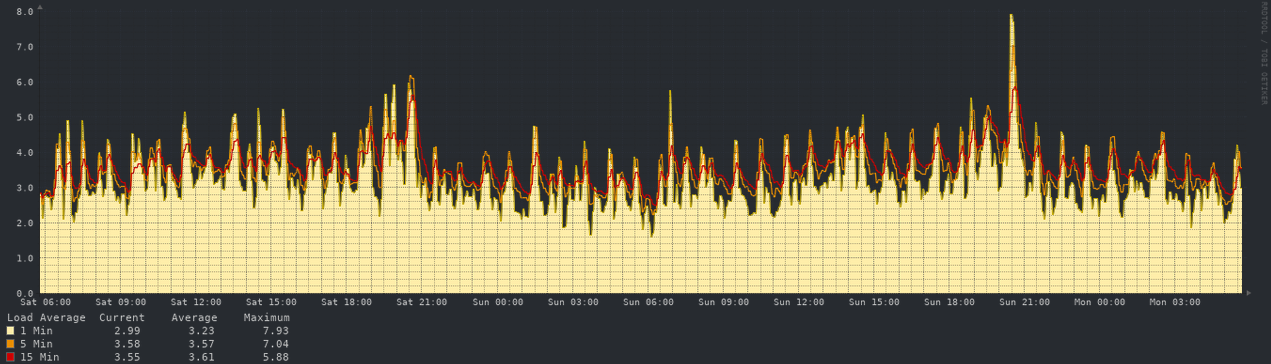
Load Average - 48 hours
System Disk I/O - 48 hours
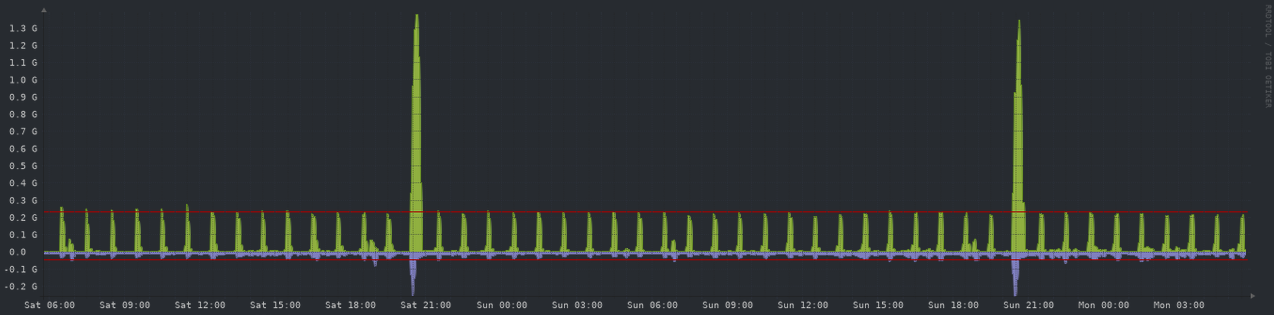
A little update for all of you interested. I allocated the additional resources to the VM and will post some updated graphs once they update with the new configurations.
For those who are like me and like looking at graphs here are some prior to the upgrade.
CPU - 48 hours
Memory - 48 hours
Network - 48 hours
so if I’m reading this right, less than 10% CPU capacity and about 1/8th ram at peak times, before upgrades? gotta give you credit where it’s due, that thing looks ready to take some abuse.
The only part I don’t have graphed yet is the disk IOs. I’m going to need to invest a little more time to get that metric going captured.
Say you through 1000s of active users to this instance… what would cause the bottle neck first? CPU, memory, network, disk? I’m thinking probably disk due to database optimization that need to be reworked on lemmy afterwards CPU and then memory.
Yeah disk iops is probably is gonna be the biggest hurdle, but so far so good…
The server doesn’t have any users atm though
Hello Lemmy! I’ve just made an account to get my foot in the door incase the Reddit execs don’t roll back after the blackout, let’s sit back and watch the fireworks.