Updated to RealVisXLTurbo. Image generations ~10 seconds. Uses GPT-4 Visions to generate prompts for images and SDXL with Controlnet for image generation.
I built this for myself because I kept putting in 18th century etchings or ruined frescoes into chat GPT to see what they looked like in real life. I’ve always been interested to see marble statues in flesh too.
My problem is that reconstructions by architects are produced differently, using more information, than Hollywood-like DALL-E outputs. The first one is made to be informative, about the size and aspect of the buildings, the urban organization, etc. The second one is just designed to look good.
Not entirely – This uses controlnet to mimic the lines and shapes in the original image – It’s finicky getting the settings right so it works well in all cases, but this is more than just a straight img2img conversion or DALLE txt2img generation.
This is indeed a good example. You literally just give it squares to fill with whatever the model feels makes sense and as a result you have christian looking fresco probably very far from the likely reconstructions archaeologists would produce (the red parts were likely totally red, without characters in them).
I feel that applied like that it is closer to misinformation than enhancement.
Well, not exactly again – The original image is passed to GPT4 vision along with the article title and the image’s description, so it’s attempting to be contextual in its prompts and contextual to the shapes in the original image.
Ah sorry, I did not realize you were the author, I would have been less brutal. Then let me rephrase my criticism: I think it is unproductive to show reconstruction of statues or painting of archaeological interest. Maybe showcase it more on enhancement of black and ,white pictures or sci fi illustration ?


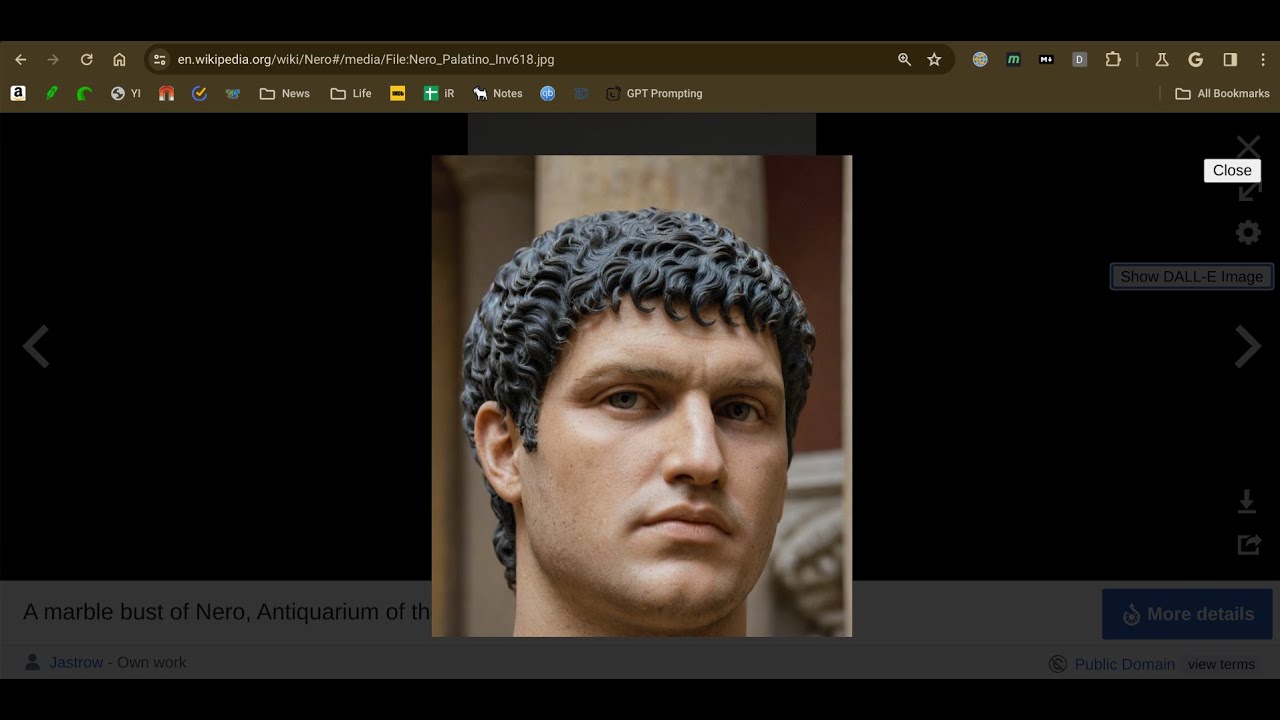
I built this for myself because I kept putting in 18th century etchings or ruined frescoes into chat GPT to see what they looked like in real life. I’ve always been interested to see marble statues in flesh too.
This is not AI generated or the same thing, but partially what I think put the idea in my brain – https://tenochtitlan.thomaskole.nl/
How cool is that? Feels like you’re there almost. I’ll take that over some timeworn painting, which is not truthful either – Ceci n’est pas une pipe
My problem is that reconstructions by architects are produced differently, using more information, than Hollywood-like DALL-E outputs. The first one is made to be informative, about the size and aspect of the buildings, the urban organization, etc. The second one is just designed to look good.
Not entirely – This uses controlnet to mimic the lines and shapes in the original image – It’s finicky getting the settings right so it works well in all cases, but this is more than just a straight img2img conversion or DALLE txt2img generation.
This is a good example:
original wiki image
SDXL Controlnet image
This is indeed a good example. You literally just give it squares to fill with whatever the model feels makes sense and as a result you have christian looking fresco probably very far from the likely reconstructions archaeologists would produce (the red parts were likely totally red, without characters in them).
I feel that applied like that it is closer to misinformation than enhancement.
Well, not exactly again – The original image is passed to GPT4 vision along with the article title and the image’s description, so it’s attempting to be contextual in its prompts and contextual to the shapes in the original image.
And it fails.
I am pleased with it and its potential, especially for a v1. It’s OK that you don’t feel the same way.
Ah sorry, I did not realize you were the author, I would have been less brutal. Then let me rephrase my criticism: I think it is unproductive to show reconstruction of statues or painting of archaeological interest. Maybe showcase it more on enhancement of black and ,white pictures or sci fi illustration ?
all good thanks for the feedback! This will probably end up being the foundation for my weeb targeted saas app cash grab :P
Really fun tech project and supabase.com I’ve fallen in love with I think – best dev experience ever maybe