
{kind=link}
- cross-posted to:
- technology
- cross-posted to:
- technology
Previous posts: https://programming.dev/post/3974121 and https://programming.dev/post/3974080
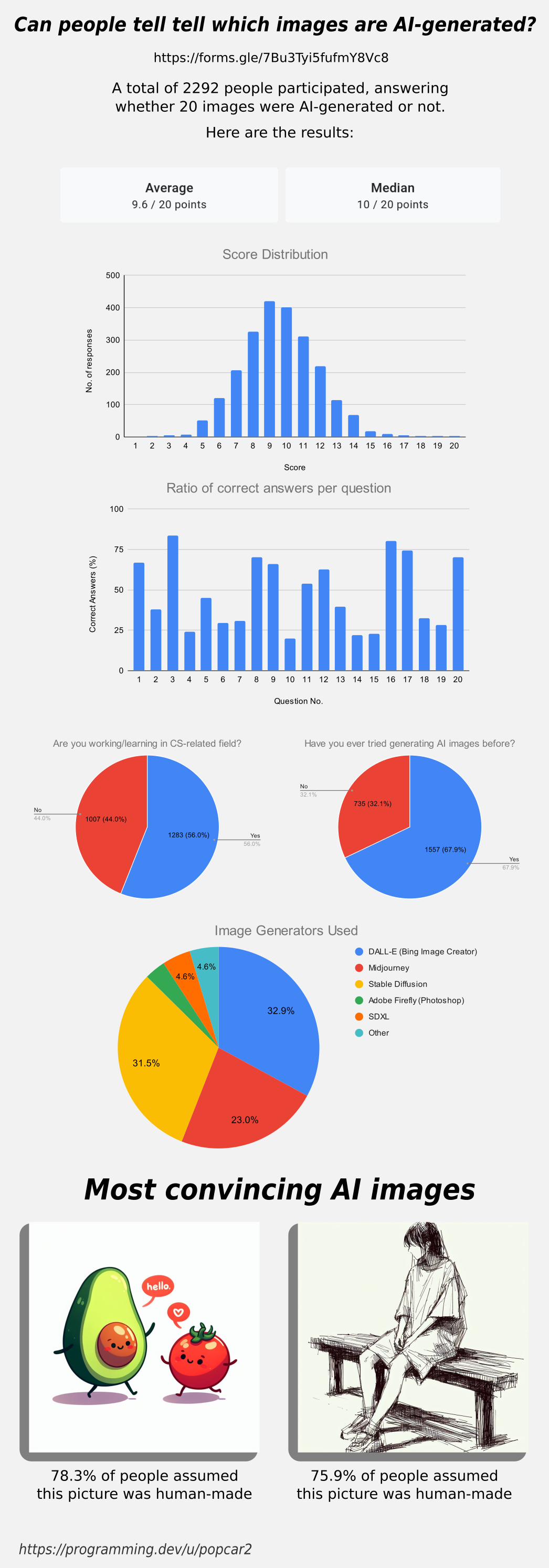
Original survey link: https://forms.gle/7Bu3Tyi5fufmY8Vc8
Thanks for all the answers, here are the results for the survey in case you were wondering how you did!
Edit: People working in CS or a related field have a 9.59 avg score while the people that aren’t have a 9.61 avg.
People that have used AI image generators before got a 9.70 avg, while people that haven’t have a 9.39 avg score.
Edit 2: The data has slightly changed! Over 1,000 people have submitted results since posting this image, check the dataset to see live results. Be aware that many people saw the image and comments before submitting, so they’ve gotten spoiled on some results, which may be leading to a higher average recently: https://docs.google.com/spreadsheets/d/1MkuZG2MiGj-77PGkuCAM3Btb1_Lb4TFEx8tTZKiOoYI
The training data containing non licensed artwork is an extremely short term problem.
Within even a few years that problem will literally be moot.
Huge data sets are being made right now explicitly to get around this problem. And ai trained on other AI to the point that original sources no longer are impactful enough to matter.
At a point the training data becomes so generic and intermixed that it’s indistinguishable from humans trained on other humans. At which point you no longer have any legal issues since if you deem it still unallowed at that point you have to ban art schools and art teachers functionally. Since ai learns the same way we do.
The true proplem is just that the training data is too narrow and very clearly copies large chunks from existing artists instead of copying techniques and styles like a human does. Which also is solvable. :/