
I thought some people were out there in June creating stress-testing scripts, but I haven’t seen anything materializing/showing results in recent weeks?
I think it would be useful to have an API client that establishes some baseline performance number that can be run before a new release of Lemmy and at least ensure there is no performance regression?
The biggest problem I have had since day 1 is not being able to reproduce the data that lemmy.ml has inside. There is a lot of older content stored that does not get replicated, etc.
The site_aggregates UPDATE statement lacking a WHERE clause and hitting 1500 rows (number of known Lemmy instances) of data instead of 1 row is exactly the kind of data-centered problem that has slipped through the cracks. That was generating a ton of extra PostgreSQL I/O for every new comment and post from a local user.
The difficult things to take on:
-
Simulating 200 instances instead of just 5 that the current API testing code does. First, just to have 200 rows in many of the instance-specific tables so that
local = falseAPI calls are better exercised. And probably about 25 of those instances have a large number of remote subscribers to communities. -
async federation testing. The API testing in lemmy right now does immediate delivery with the API call so you don’t get to find out the tricky cases of servers being unreachable.
-
Bulk loading of data. On one hand it is good to exercise the API by inserting posts and comments one at a time, but maybe loading data directly into the PostgreSQL backend would speed up development and testing?
-
The impact of scheduled jobs such as updates to certain aggregate data and post ranking for sorting. We may want to add special API feature for testing code to trigger these on-demand to stress test that concurrency with PostgreSQL isn’t running into overloads.
-
Historically, there have been changes to the PostgreSQL table layout and indexes (schema) with new versions of Lemmy, which can take significant time to execute on a production server with existing data. Some kind of expectation for server operators to know how long an upgrade can take to modify data.
-
Searching on communities, posts, comments with significant amounts of data in PostgreSQL. Scanning content of large numbers of posts and comments can be done by users at any time.
-
non-Lemmy federated content in database. Possible performance and code behavior that arises from Mastodon and other non-Lemmy interactions.
I don’t think it would be a big deal if the test takes 30 minutes or even longer to run.
And I’ll go out and say it: Is a large Lemmy server willing to offer a copy of their database for performance troubleshooting and testing? Lemmy.ca cloned their database last Sunday which lead to the discovery of site_aggregates UPDATE without WHERE problem. Maybe we can create a procedure of how to remove private messages and get a dump once a month from a big server to analyze possible causes of PostgreSQL overloads? This may be a faster path than building up from-scratch with new testing logic.
The API calls to do schedule job manual run could be of use to production server operators too, admin privilege required. I think for testing of ranking / sorts - if we could simulate the passage of time to validate “Hot” and “Active” are showing the posts / aging out old content / etc. Any suggestions about how to go about this, please chime in. Thank you.
On the topic of real-world data on production live servers… on Friday I discovered a unusual situation with a comment that will not display in some circumstances.
If you look at this remote user profile on Lemmy.ml running 0.18.3 https://lemmy.ml/u/ohai@subsubd.com?page=1&sort=Old&view=Comments the Oldest comment, and click on the link to the comment itself… it doesn’t load. This comment:
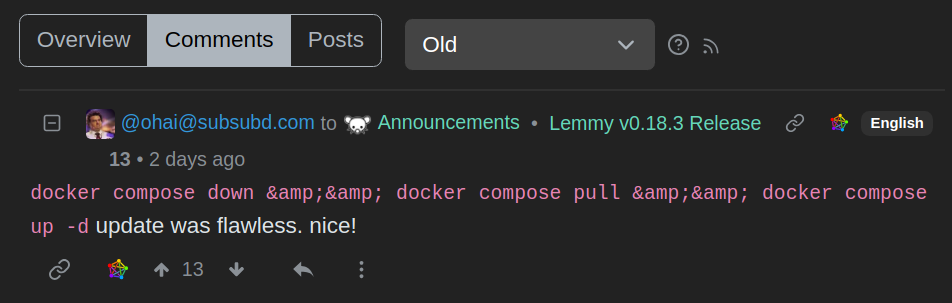
In situations like this, the raw PostgreSQL records would be interesting to study. And some kind of way to export that raw data related to a posting… sort of like being able to take a biopsy off a living human to go into the laboratory to diagnose further. It could really save a lot of time getting bugs specific to data tracked down and reverse-engineering the client API calls to make test cases for them.
Anyone have numbers to share as to the storage size, gigabytes, within PostgreSQL for a fully populated database right now for Lemmy.ml / lemmy.world or other server that subscribes to almost everything in the lemmy network?
I’m going to guess it’s in the 4 to 20 gigabyte range? maybe excluding the activity tables it is less? (just PostgreSQL, not images)
On a similar note, has anyone been publishing their Prometheus data?