There are also issues lurking with accumulation of data. Moving to a batch processing system might want to consider that some instance operators may only wish to retain 60 days of fresh content vs. having every single history of content for a community for search engines and local-searching. The difference in performance is huge, which is why popular Lemmy servers have been crashing constantly - the amount of data in the tables entirely changes the performance characteristics.
Right now, Lemmy has no concept of tiered storage or absent content from replication or purge choices. Looking from the bottom-up, API client before touching PostgreSQL - a smart caching layer could even proxy to the API of a peer instance and offer a virtual copy (cached) of the data for a listing or post. Such a design could intelligently choose to do this for a small number of requests and avoid burdening PostgreSQL with the storage of a post from months or years ago that a few people take a recent interest in (or a search engine wants to pull a copy of old posts).
In the API middleware of remote-instance, I am assuming that could be implemented with some leverage of the existing design of Lemmy 0.18.2
Let’s assume some basic scaling enhancements are made to lemmy
-
community_aggregate keep track of timestamps of: post, post edit, comment, comment edit. Votes are more tricky, but that could be updated in batch too. Comment votes can probably be ignored in favor of post votes only. last post vote change anywhere in the community.
-
replication of aggregates for both person and community becomes a feature of Lemmy similar to how profile of community and person are replicated.
Ok, so a site could analyze that a community is well suited for remote stub instead of full copy.
-
Only reading would pull from the API. For authentication/API sake, adding creation/edit of local comments and posts would go through local process of a stub community’.
-
Existing federation could be enhanced: for incoming federation receive logic look if a stub-community and not actually INSERT new comments and posts into PostgreSQL and set a timestamp flag on community_aggregates that the cache is dirty. Alternate implementation could be receive as normal and to purge anything older than 24 hours once a day from stub communities.
-
On July 18, this comment was made on a pull-request:
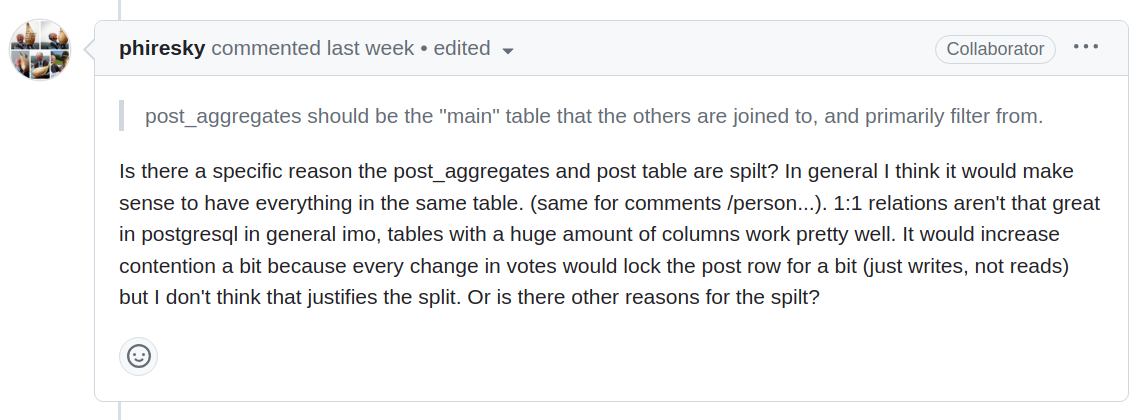
One major reason I can see for maintaining a split is storage tiers. post_aggregates can know of a post in a community without actually having to hold the content body in PostgreSQL. API to another Lemmy server could fetch the content or non-PostgreSQL.
This is an area where Lemmy might be well place for scaling.