All I am doing is irritating people.
In the Lemmyverse: People seem to enjoy upgrading hardware to huge numbers of cores, adding big-brand front-end commercial DDOS protection, but do not like !lemmyperformance@lemmy.ml discussion on Lemmy itself (eat your own dog-food, developers is not a mantra, as I’ve said here before).
Each new local comment and post on a local server updates 1800 rows in site_aggregates, but there seems no urgency to get the fix out first thing Monday- and stop every large Lemmy server from crashing so frequently. I put “emergency” in the pull request title, leadership edited it out. That says it all. EVERY ONE of the major servers is crashing on my personal visits all weekend, Monday, now Tuesday.
I bring up a direct topic of engineering deletes for scale and concurrency and get push-back from the players on GitHub that that’s off-topic to the delete crashing problem, and I have to lecture them on autism mental differences, which they can’t wait to be irritated by. What a shock, people who find autistic thinking irritating and different from what they think.
It’s the lack of testing and sharing the backend data directly that nobody even noticed these things (site_aggregates has 1700 rows, all getting increments for every new post and comment). And push back on every code that doesn’t pass beautification tests or has an unused testing function in it - it’s like a massive corporation where people only work 9 to 5 and find every excuse to say “not my problem” when it comes to servers crashing every hour.
So the first hour of work on GitHub, sanitizing emails and enabling gzip compression seems to be a priority. Crashing servers still not a project priority. but the tiny number of people who use an e-mail feature that could be disabled during the server-crashing crisis… is getting the attention. Back on June 1 when the servers were crashing I was confused, but that’s kind of the point, is’n’t it?
Social hazing still the best answer I can come up with, not just developers, but every newcomer to the project… the front page of the GitHub bragging “full delete” and “high performance” - lays the foundation for the entire project, even typical end-users, to go down that path. People rarely discuss why hazing evolves in some business and especially military and school structures, and it shows up across a variety of demographics. It isn’t a money motivation, it’s a social focus in most cases. For me, it’s a new experience to witness it see it utilized on the scale of an entire multi-operator organization - all the newcomers and established server operators. lemmy.ca took it in their own hands to track down the performance bug that had sat on GitHub for over 30 days… that server has been around since December 28, 2020 at least - so they have a lot more experience with the priorities of developers on performance - and got into detailing the SQL crashes directly. Hazing is really something to witness.
Are they hazing newcomers to the project?
The site_aggregates table has id AND site_id field. Why would there even be a site_id field on the table if there was no intention for it to have 1800 rows for 1800 Lemmy instances? On my production server, it has rows for every instance.
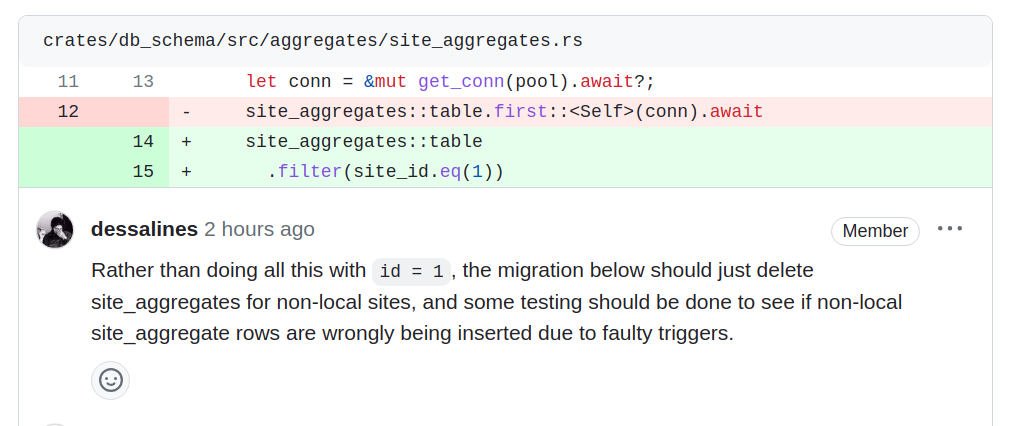
I’m not joking, is this all hazing or some other social game to prevent emergency changes going out to provide relief to crashing servers?
I worked on new testing code that I now added to the pull request. But 6 hours since I made this comment, I just can not shake the behavior over the past 60 days and the pattern of focusing on a “new Rust client” instead of servers crashing all the time. It must be a social strategy. Not only does hazing social behavior explain the way they are acting, it’s the only way I can see the GitHub front page of the project bragging about “high performance” and “full delete”. It must be their sense of creating mental challenges, a form of hazing, on newcomers.
I guess it isn’t just Elon Musk that has cult followings in technology. Crashing servers and such seem ‘cool’ to the development leaders as they go off and create an all-new Rust client when a dozen new client apps were already independently being developed. Nobody criticizes them for starting a all-new client application while massive problems are in lemmy_server.
The server crashes and the lack of pull request to actually address server crashes speak for themselves, regardless of my observations here and on GitHub. The hardware upgrades were not mentioned on GitHub, and that says a lot too - just considered not to be relevant to the design and implementation of the crashing code.
Was it PostgreSQL that was flailing, or lemmy_server code updating 1700 rows when it only needed to update 1. There is no ownership of such a mistake going into production. No sense of urgency to fix mistakes that are obvious contributors to server crashes.
“let the end users eat cake” with the crashing severs on routine calls to save a comment or even can’t get logged in with 2FA enabled - while another new Rust front-end is started.
The performance priorities of the Rust code itself reflect their lack of concern for performance in addressing server crashes, knowing they are the only Rust developers with Diesel experience who can get the changes in. Instead of fixing bugs, doing quality control, they start a new client project in Rust.
Me: "This is an urgent test addition to highlight the problem with comment deletes not replicating when a remote-server creates the comment, the community home server has no code to replicate delete of comment to all the downstream subscribed servers. "
July 18. Today is July 25. No sense of urgency that the front page of the project on GitHub brags about “Full delete” social media. But starting a new Rust front-end application…
Testing and fixing server crash seems nobody priority.
I opened an issue July 17 about how the testing servers aren’t even testing the code. No response still as of July 25. Servers crashing left and right every day for 2 months. But a new front-end in Rust is being started…
Tick tock, time keeps passing, week after week, of servers crashing. And nobody wants to make fixing the SQL and adding test code a priority. Let the end-users eat cake while Elon Musk rebrands from 'twitter to X", growing the federverse - and Lemmy is crashing. It isn’t just Reddit that is sending users here, it’s major changes, yet no sense of urgency to fix the back-end performance and data integrity issues.
An issue opened by someone else, July 12, about how back-end 18.2 didn’t even get a RELEASE on GItHub has been ignored: https://github.com/LemmyNet/lemmy/issues/3602
A guy today concluded that the Mali government removed lemmy.ml - not realizing that the constant crashes today continue to be ignored by the Lemmy developers who will not prioritize performance critical crash-fix changes into production servers.
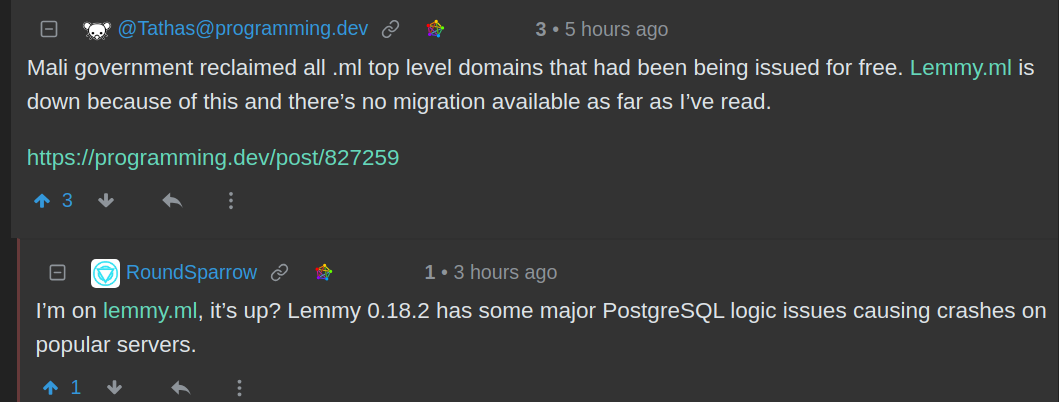
People have some blind faith that the developers would actually try to fix the server crashing problem other than adding more cores to the hardware. 1700 row UPDATE SQL instead of 1 row, not a Monday priority or a Tuesday one it seems!
All dressed up, but people can’t post or comment because servers keep crashing. New clients everywhere, nobody wanting to proofread a PostgreSQL trigger function and provide feedback.
100 waiters ready to serve on the front end, but no staff in the kitchen.
today a post on lemmy.world about people experiencing server crashes: https://lemmy.world/post/2141374