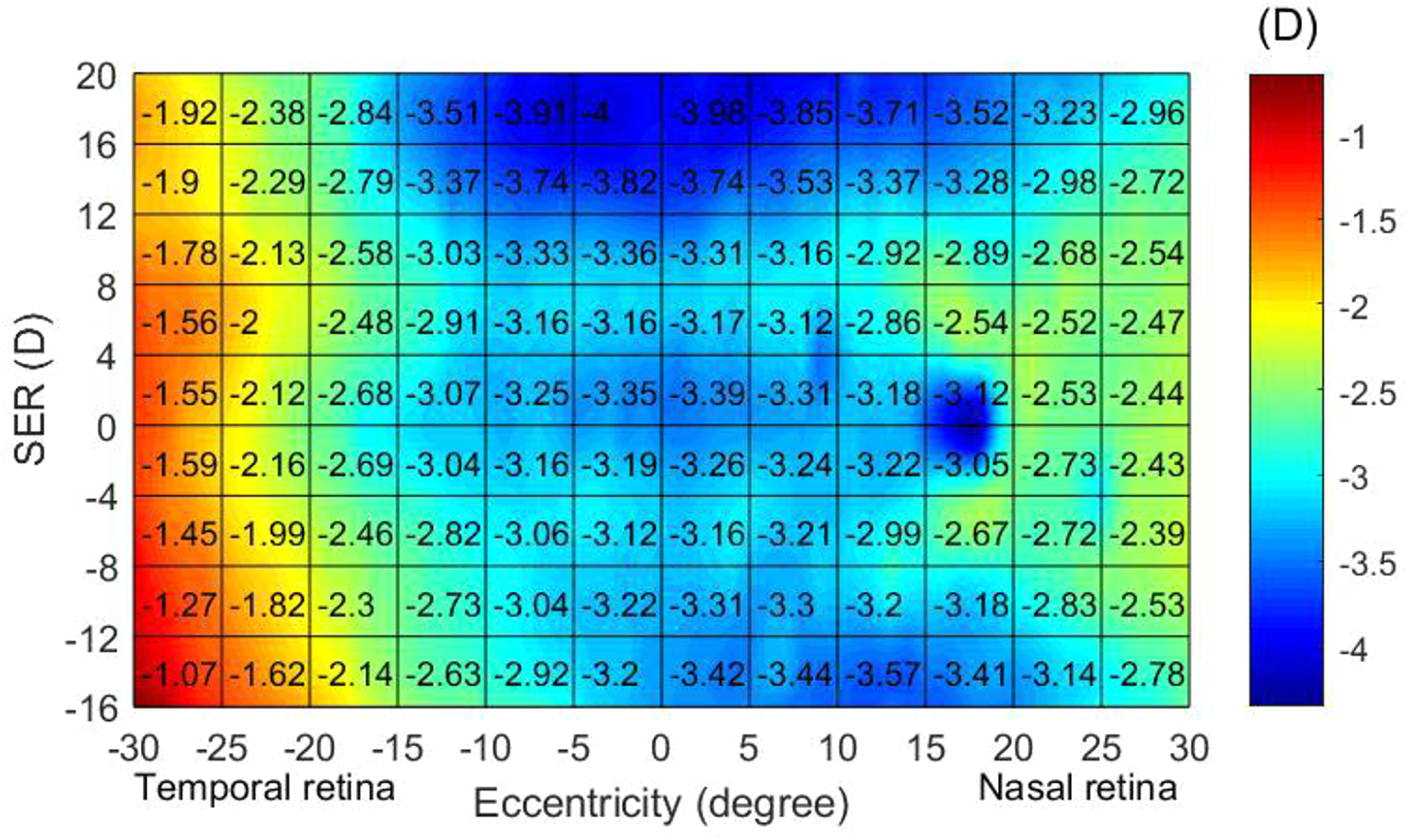
The question of whether artificial intelligence (AI) can surpass human capabilities is crucial in the application of AI in clinical medicine. To explore this, an interpretable deep learning (DL) model was developed to assess myopia status using retinal refraction maps obtained with a novel peripheral refractor. The DL model demonstrated promising performance, achieving an AUC of 0.9074 (95% CI 0.83–0.97), an accuracy of 0.8140 (95% CI 0.70–0.93), a sensitivity of 0.7500 (95% CI 0.51–0.90), and a specificity of 0.8519 (95% CI 0.68–0.94). Grad-CAM analysis provided interpretable visualization of the attention of DL model and revealed that the DL model utilized information from the central retina, similar to human readers. Additionally, the model considered information from vertical regions across the central retina, which human readers had overlooked. This finding suggests that AI can indeed surpass human capabilities, bolstering our confidence in the use of AI in clinical practice, especially in new scenarios where prior human knowledge is limited.
All programs were developed in Python language (3.7.6). In addition, freely available Python libraries of NumPy (1.18.1) and Pandas (1.0.1) were used to manipulate data, cv2 (4.4.0) and matplotlib (3.1.3) were used to visualize, and scikit-learn (0.24.2) was used to implement RF. SqueezeNet and Grad-CAM were realized using the neural network library PyTorch (1.7.0). The DL network was trained and tested using a DL server mounted with an NVIDIA GeForce RTX 3090 GPU, 24 Intel Xeon CPUs, and 24 GB main memory
it’s interesting that they’re using pretty modest hardware (i assume they mean 24 cores not CPUs) and fairly outdated dependencies. also having their dependencies listed out like this is pretty adorable. it has academic-out-of-touch-not-a-software-dev vibes. makes you wonder how much further a project like this could go with decent technical support. like, all these talented engineers are using 10k times the power to work on generalist models like GPT that struggle at these kinds of tasks, while promising that it would work someday and trivializing them as “downstream tasks”. i think there’s definitely still room in machine learning for expert models; sucks they struggle for proper support.
I’d say the opposite. Usually you barely get the requirements.txt, when you do you’re missing the versions (including for python itself), and then only must you find out The versions of cuda and cuda driver


it’s interesting that they’re using pretty modest hardware (i assume they mean 24 cores not CPUs) and fairly outdated dependencies. also having their dependencies listed out like this is pretty adorable. it has academic-out-of-touch-not-a-software-dev vibes. makes you wonder how much further a project like this could go with decent technical support. like, all these talented engineers are using 10k times the power to work on generalist models like GPT that struggle at these kinds of tasks, while promising that it would work someday and trivializing them as “downstream tasks”. i think there’s definitely still room in machine learning for expert models; sucks they struggle for proper support.
I’d say the opposite. Usually you barely get the requirements.txt, when you do you’re missing the versions (including for python itself), and then only must you find out The versions of cuda and cuda driver
Appendix A of this paper is our requirements.txt