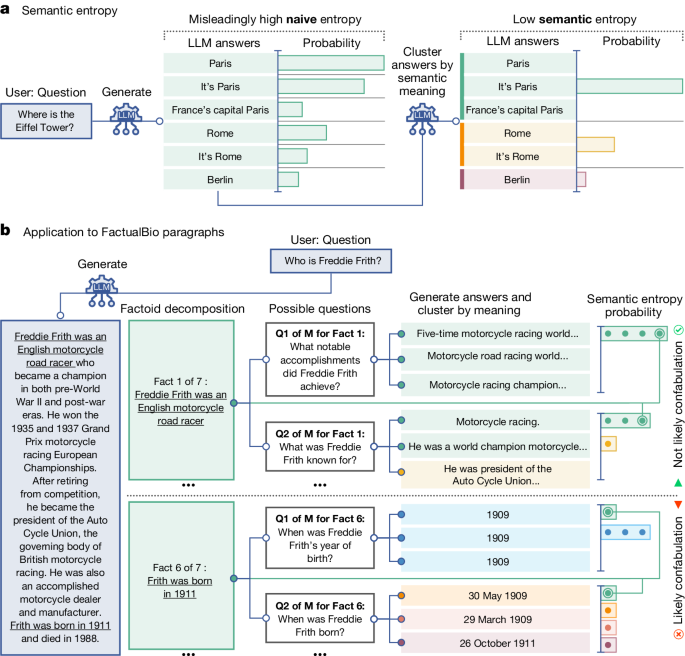
Hallucinations (confabulations) in large language model systems can be tackled by measuring uncertainty about the meanings of generated responses rather than the text itself to improve question-answering accuracy.
LLMs were designed to generate coherent statements, but not necessarily correct ones, and are unable to consistently spot logical fallacies in their output. Humans can do this (some better than others), so computers should be capable of this too. The technology is not there yet, but I’m glad people are working on it.


LLMs were designed to generate coherent statements, but not necessarily correct ones, and are unable to consistently spot logical fallacies in their output. Humans can do this (some better than others), so computers should be capable of this too. The technology is not there yet, but I’m glad people are working on it.