Test message #2 in this comment section of this posting
You KNOW WHY nobody does testing and finds these problems? Because it’s hard work, nobody wants to do it.
And when you actually go around and TEST federation by hitting Beehaw, Lemmy.world, Lemmy.ml, your own server, and a half dozen of the small ones - it takes TIME and EFFORT.
They they ignore you as to how important it is to get the crash logs off the big servers. Actual testing that you spent 80+ hours on in 14 days they don’t seem to think is of any value.
The project SHOWS that they don’t think TESTING and Quality Assurance is of much value. That’s been the attitude I keep seeing, that testing isn’t a priority! That sharing crash logs of the Rust code isn’t important!
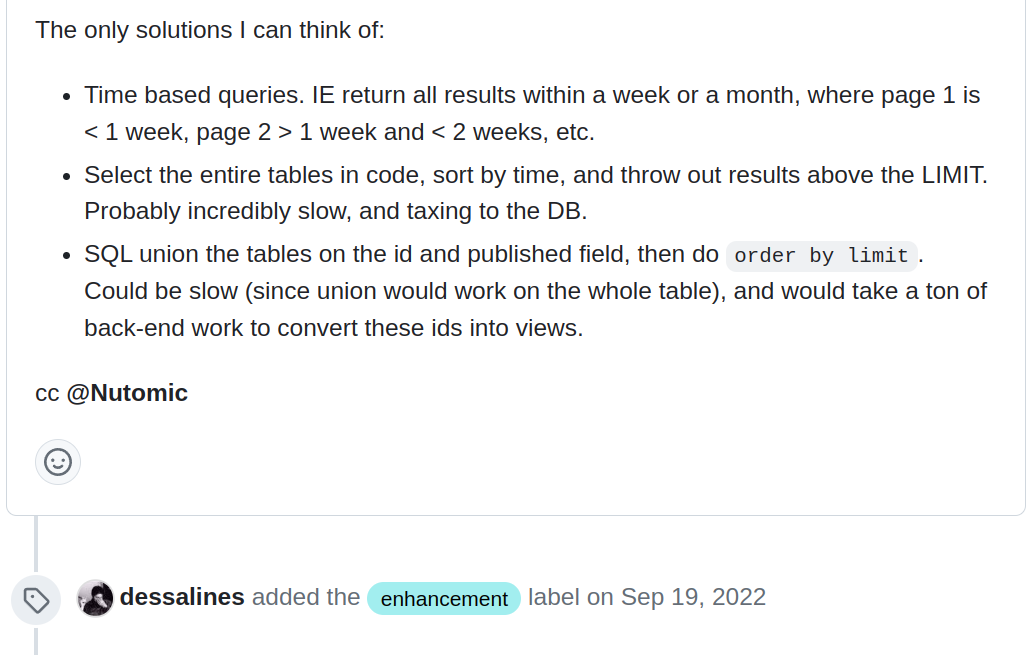
I’ve revisited this GItHub discussion now at least 5 times in the past 4 weeks.
this needs major editing, but throwing it into raw journal:
Time based queries. IE return all results within a week or a month, where page 1 is < 1 week, page 2 > 1 week and < 2 weeks, etc.
I think time is really important to the whole application, because user activity is almost always centered around a small number of postings in the total database.
For purposes of discussion, assume voting isn’t real time, because votes are a write activity that you may want to prioritize (meaning shed features under heavy load or minimize server resource usage if a person wants to operate that way).
If you can really focus on user activity, comments and postings have pretty strong patterns of what is “current”. Most people don’t go past into posts that are more than a few days old. You have to worry about search engines and crawlers hitting all your old content and working the database, but really the times you need the performance most - you really are working with a small percentage of the total posts and comments in the system.
Select the entire tables in code, sort by time, and throw out results above the LIMIT. Probably incredibly slow, and taxing to the DB.
The comments table alone is too much data. But I do think you could select entire POSTINGS with all their comments, and cache them in an intermediate format so you do not have to go to SQL for every single page refresh. And some timer-based invalidation (say 1 minute) to rebuild that cached data.
I remember when Reddit used to archive all posts after 6 months, they eventually got their performance so good on when to rebuild pages that they didn’t do that. But I think their approach was a good direction as an immediate development goal.
Getting private messages. from Lemmy users who say “go back to spez”. The Lemmy Community can call out the leadership of Reddit by name, they drone on and on about hate being a core value in hteir life, and how hating on spez is so important.
But when you have valid documented criticisms of the Lemmy leadership not reporting their server crashes and sharing crash logs, they private message you - because saying things out loud in public isn’t how Lemmy is run. “High Performance” is on the front-page of Github for the project, and if you have something to say about that, you are the one who needs to be socially “corrected”.
Here is what I’m getting in private messages because I keep pointing out that the major sites are not opening bugs on Github and sharing the crash logs:
-
I don’t want features, I think the “High Performance” claim is a big problem of project communications and expectations.
-
I think the site is crashing constantly, every day, for 32 days I’m using it for 6 hours a day. Nobody is reporting the crashes, and nobody seems to even notice them who is running the project. Where are the announcements that data is being lost?
-
Caching and turning off features/code, such as the “activity” database table, are obvious ways to deal with a crashing server. Yet they obviously aren’t being implemented. A caching layer between the API and the SQL database would provide immediate relief. This isn’t a “feature”, this is essential changes in a critical time period for the project.
Testing, I personally went around sharing information about testing, because the project isn’t getting enough testing… The person who private messages me seems to think that posting on Lemmy and testing Lemmy and identifying the problems doesn’t matter.
Server logs need to be shared. That’s really really really holding back the project. Caching needs to be added.
This message made it from Lemmy.ml to my server, that’s good
It also says a ton that they private messaged me back in June 25, 2023 before the Reddit June 30 API cutoff influx… as they didn’t want to be PUBLIC as to their wild non-technical claims that Lemmy PostgreSQL and lacking of caching - performance didn’t have fundamental flaws in it.
the site_aggregates UPDATE 1500 rows problem in the code is just one example of the crashes going on June 25 that was not getting attention. GitHub Issue 2910 was being ignored on June 25… and not addressed at all - a know site crashing problem.
-
Today I witnessed that Beehaw, Lemmy.world, most of all Lemmy.ml are crashing . Just 10 minutes of reading routine postings and comments
It has been this way every day since I started reading and before I even created an account. Reddit users kept recommending Lemmy - so I did eventually create an account on June 2. https://lemmy.ml/u/RoundSparrow
No issues from any of these major servers has been opened on GitHub saying “my server is crashing constantly”, I’m baffled how all month this crashing has been going on in the application - and they are acting as if business as usual.
There were almost no messages in the databases of Lemmy.ml when I first started reading it 32 days ago. There were numerous communities that had been abandoned for years.
Reported crashes on meta Lemmy.ml today, ignored like when I reported nginx 500 errors. Server operator doesn’t open issues on GirHub and seems to not care about the reports I am reading throughout the community that the site is crashing constantly.
There is a tone of intellectual dishonest that I keep sensing within the project. The “High Performance” claim on the front of GitHub really lures people into the project “it can run on a Raspberry Pi” claim.
The idea that a caching layer of the repeat SELECT statements keeps getting ignored. I shared this link on Lemmy and GIthub recently, and not one response: https://www.reddit.com/r/rust/comments/zvt1mu/comment/j1uxjs5/?utm_source=share&utm_medium=web2x&context=3
It’s a “reality distortion field” gong on. Well meaning people keep defending the management of the Lemmy.ml server - but the lack of opening a bug about the server crashes is harming the entire project. It is the core hub of federation for key communities, and now there is more chaos than ever because everyone flocked to new servers - only adding to the crashes of federation sharing.
10 second timeout on HTTP default.
The home page of GitHub should really be changed away from “High Performance” into 'we are in urgent need of fixing stability in http and database, we need scaling help with Rust and a caching layer".
I’ve spent now well over 80 hours the past 14 days testing the big Lemmy servers and in total disbelief that they aren’t opening GitHub issues and sharing their Rust crash logs. It really seems sharing the logs is something they won’t touch with a 10 foot pole, for a server application.
Test message #1
