

- cross-posted to:
- technology@lemmy.world
- kagi
- cross-posted to:
- technology@lemmy.world
- kagi
You must log in or register to comment.
Downvote me into oblivion but Kagi ain’t shit. It’s a glorified Google frontend. The author is right that the web is filled with AI generated articles and fake reviews and lists but Kagi is not immune to this enshittification.
I even tried the same query the author was removed about. Here is Kagi’s first two links for top 10 air purifiers. Notice how the first result is a BS website called top10.com and the second one is one of the “fake review” websites .

And here is Google’s. First result is Wirecutter, and this might be subjective but I trust Wirecutter reviews on most things.


Rest of the Google results are exactly what the author was mentioning. But Kagi was no different.

So $10/month to get the same shit? No thank you. I agree that Google turned to shit compared to what it was but it is still the best search engine out there. Now if the article was about privacy concerns then they would have a point. Which is what Kagi is all about anyway. So let’s stop the fucking act.
I pay nothing for running SearXNG locally on my machine.
It’s not even comparable in quality. It’s like almost trolling to even suggest they are in the same league. If you don’t want to spend 10 dollars, fine, but maybe stop pretending that your instance is somehow the best quality search engine that exists… :)
On top of that they’re still paying using their time (and power).
Your argument clearly shows that you fail to see the benefits of doing it yourself. I get quality results from my local instance due to my persistence and work put in to adjust the settings necessary. I’ve balanced the privacy and functionality of the instance to fit my needs and it costs me nothing but a few minutes of my time each week to do so.
Kagi doing it for $10 a month sounds like they’re turning a neat profit off of you; and you’re refusing to accept that I have achieved levels of search competence that Kagi has without paying for Kagi or even using their free searches or service.
Whether or not it makes sense to you value-wise to pay or not pay for Kagi does not matter in this discussion. it only matters that none of the things Kagi can do that I find useful are things that cannot be done with SearXNG.
That is the way to go.
The nice thing is that I can customize it however I like too; change weights, choose which engines to pull from always, or even from search to search; so I’m not getting cruft.
SearXNG always rearranges the crap most engines serve to the bottom without fail.
But is it deterministic? That has been my main complaint. Every time you see someone else’s results try the same thing and see what you get. Odds are it will be very different and that is a problem.
The best example I can give is searching for hardware documentation for chips. If some asshat company pays google and m$ for promotion it does not matter what I search for I will not get relevant results. I am never searching for a product to buy. Every result will be for this irrelevant shit company and filler junk both engines know to be incorrect. It does not matter where I search. There are effectively only two crawlers that exist. My inquiry is unique enough that all searches fall into the same irrelevant garbage echo chamber. I mostly quit trying to program stuff I’m interested in because of this behavior. I haven’t found a way around it that works. I had the same problems regardless of VPN, or public SearX instances. I don’t know how self hosted would change this. I get the impression that some algorithm jokingly allows some people through once it establishes their identity and a monetization path. When the network and device are never used for purchases, it’s shit all the way down.
TIL of this. Thanks.
My understanding is that a locally hosted SearXNG instance doesn’t really give you any privacy, unless you “dilute” your searches by letting others do searches from your instance too.
Route it through a vpn with gluetun and it does…
To be honest the “Privacy” aspect can be taken care of in other ways; like using a VPN for query dilution, for example. You don’t have to recruit 100 mechanical turks to do junk searches for you; although there are browser addons that can in fact do this automated searching for you…I’ve run them before.
SearXNG is a front-end that protects your privacy still. Hosting it locally dilutes it some; but provides maximal control; as you can use VPNs and control things much more tightly than you could if you hosted it elsewhere.
Your search results look very different to mine:
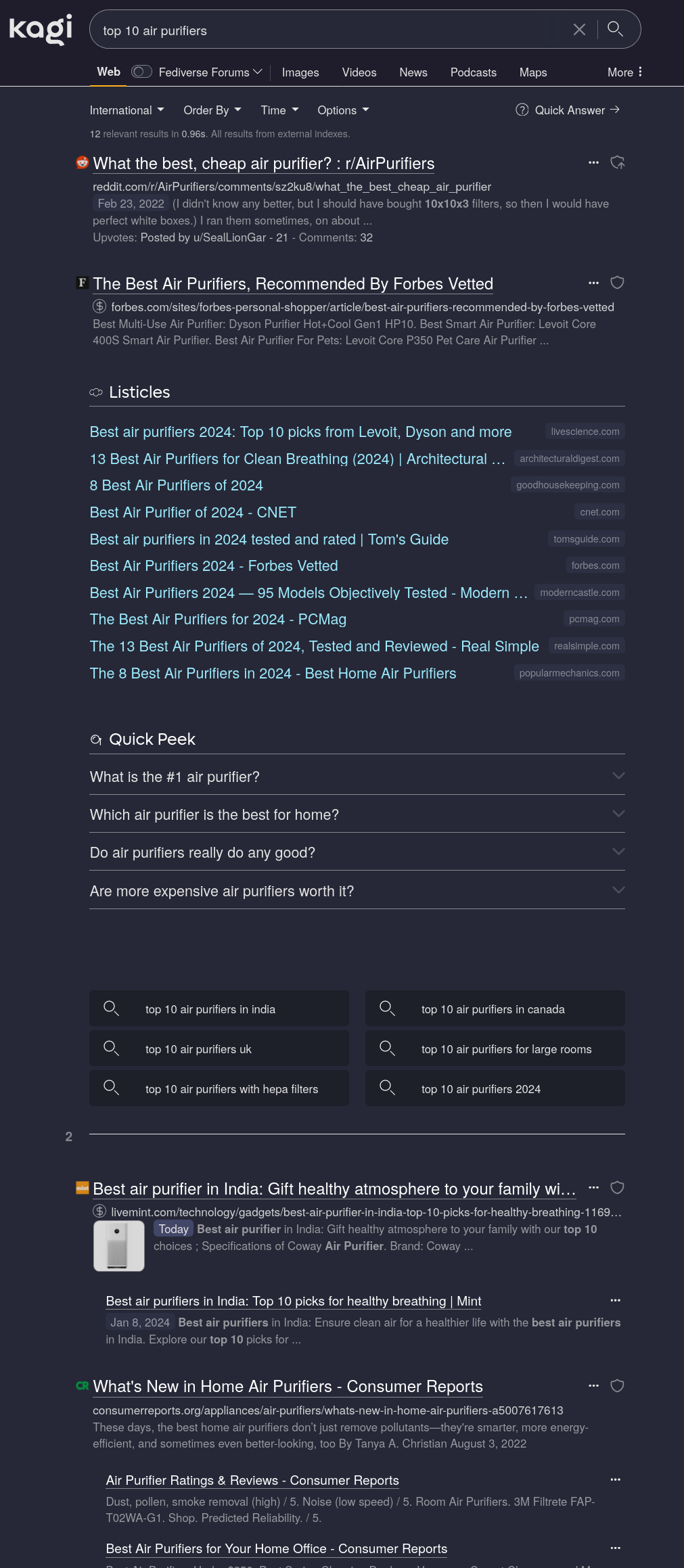
Did you disable Grouped Results?
All the LLM-generated “top 10” listicles are grouped into one large block I can safely ignore. (I could hide them entirely but the visual grouping allows for easy mental filtering, so I haven’t bothered.) Your weird top10 fake site does not show up.
But yes, as the linked article says, Kagi is primarily a proxy for Google with some extra on top. This is, unfortunately, a feature as Google’s index still reigns supreme for general purpose search. It absolutely is bad and getting worse but sadly still the best you can get. Using only non-Google indices would just result in bad search results.
The Google-ness is somewhat mitigated by Kagi-exclusive features such as the LLM garbage grouping.What Google also cannot do is highlighted in my screenshot: You can customise filtering and ranking.
The first search result is a Reddit thread with some decent discussion because I configured Kagi to prefer Reddit search results. In the case of household appliances, this doesn’t do a whole lot as I have not researched trusted/untrusted sources in this field yet but it’s very noticeable in fields like programming where I have manually ranked sites.Kagi is not “all about” privacy. It’s a factor, sure but ultimately you still have to trust a U.S. company. Better than “trusting” a known abuser (Google, M$) but without an external audit, I wouldn’t put too much wight into this.
The index ain’t it either as it’s mostly Google though sometimes a bit better.
What really sets it apart is the features. Customised ranking aswell as blocking some sites outright (bye bye pinterest and userbenchmark) are immensely useful. So are filtering garbage results that Google still likes to return.I didn’t change any settings. fresh account
Is “Grouped Results” disabled in settings?
I wouldn’t use “air purifier” as a metric, since it was already a big public story that surely any search engine that’s even half paying attention would have made sure the results for are good. Probably some other consumer good is better for an un-preannounced test run.
(Also I’m not sure that searching “top 10 air purifier” and complaining that you got a top result of top10.com/air-purifiers and that’s not what you wanted makes a ton of sense. FWIW, I did try “air purifier” just out of curiosity and saw a very clear result that DDG had the best results, Google second, and Kagi third.)
I repeated it for “good wireless router” and saw different results; for them, the outcomes were fairly similar with Kagi somewhat better (returning Wirecutter as the top result, and an obselete Stack Exchange answer as the 2nd, which okay it’s not right but I get where you’re coming from sir), and Google and DDG as secondary (returning PCMag and CNet at the top and Wirecutter only further down below).
I searched both Cory Doctorow’s post and the linked 404media article in his post for “air purifier” and found nothing. What author are you referencing?
Thanks.
Dunno, I got entirely different results. Reddit, homeairguides, forbes, a bunch of listicles like consumerreports, wired, ny times, cnet and whatnot, and other websites.
I’m still steering clear from Kagi after how they handled criticism after they started including Brave’s index
That whole situation was such an overblown idiotic mess. Kagi has always used indices from companies that do far more unethical things than committing the extreme crime of having a CEO who has stupid opinions on human rights.
I 100% agree with Vlad’s response to this whole thing and anyone who thinks otherwise should question what exactly it is they’re criticising.I don’t like Brave (super shady IMHO) and certainly not their CEO but I didn’t sign up for a 100% ethically correct search engine, I signed up for a search engine with innovative features and good search results. The only viable alternatives are to use 100% not ethically correct search indices with meh (Google) to bad (Bing, DDG) search results. If you’re going to tell me how Google and M$ are somehow ethical, I’m going to have to laugh at you.
The whole argument amounts to whining about the status quo and bashing the one company that tries anything to change it. The only way to get away from the Google monopoly is alternative indices. Yes those alternatives may not be much more ethical than friggin Google. So what.
You can’t really engage as a consumer without enabling shitty practices on some level, and that’s particularly true of electronics.
The phone you’re using to access Beehaw? Assembled by child labor or wage slaves somewhere in Asia. Even if you assembled it yourself, the parts were manufactured unethically.
It’s not just Amazon or Nestle. You might as well criticize someone for breathing because unethical consumption, on some level, is inevitable, particularly so if you live in a capitalist country.
I use Brave because its ad block feature works better than the others I’ve tried, plain and simple.
But, by all means, people can still be as holier than thou as they like.
The phone you’re using to access Beehaw? Assembled by child labor or wage slaves somewhere in Asia. Even if you assembled it yourself, the parts were manufactured unethically.
which is one of the reasons why I own a Fairphone.
and sure, you can’t avoid all bad choices, but everyone draws a line somewhere. and when a techbro makes a techbroy post about how eVErYThiNg iS pOLiTiCiZeD ThESe dAyS and how that’s supposedly stopping innovation, because people like me don’t want him to work with a guy with a history of opposing our rights, then I stop having confidence in him and cancel my subscription because I don’t want to support him financially anymore.
Don’t get me wrong. I do the best I can to be ethical in my choices, but it’s just a pet peeve of mine to see people behaving in a holier-than-thou when it’s simply impossible to achieve what they’re pretending to achieve.
people like me don’t want him to work with a guy with a history of oppressing our rights
Maybe I’m misunderstanding, but what search do you use that relies on a more ethical index? I don’t use SearXNG, but as far as I can tell, even something like that relies on other indices, like Google, Bing, and Brave (which seems to be configurable). Are you suggesting you use a different index that comes from a more ethical company, or do you just not like Vlad’s response?
Are you suggesting you use a different index that comes from a more ethical company
I don’t, I use a mixture of Startpage and DDG, but I’m always for a lookout for other options and also don’t sign up for a subscription to throw my money at them every month.
To add, from what I understand at least, Kagi does build its own index for accessing smaller sites. To some extent, results are also served by a custom index, meaning some percentage of results do not come from [your disliked companies] and instead come directly from Kagi. It doesn’t seem like a significant percentage of results come from that index, but it supposedly is still >0%.
Personally I mostly use Kagi for the ability to put Reddit on the bottom of the results, MDN to the top, and otherwise prioritize sites in ways that I want but which I know are purely based on my own opinions. It works well for my usecase, and I don’t have to scroll through a bunch of sponsored links before finding my search results. Also, the recent integration with Wolfram|Alpha has been convenient with a couple of searches, like one where I needed the prime factors of some numbers.
I genuinely won’t even use Brave indexes on my SearXNG instance; I have the engines disabled. My search quality has not suffered; as most of my results end up being DDG or Yahoo anyways; and Brave was only ever duplicating results from other engines anyways.
Just curious, do you buy things from Amazon?
I’m not trying at all to disagree with the idea of being ethical in how you send your dollars, but I’m curious how much is prioritized actual harm to suffering people in the real world when you do this.
Just curious, do you buy things from Amazon?
no I don’t. and to answer your next whatabout question, I don’t buy from brands owned by Nestle, either.
Good work doing what you can!
Dodging shitty companies is difficult.Got it, makes sense.
And ha, yeah sorry if it was overly snarky, I just see some people where “oh my GAWD you said the wrong thing in your press release” is their only barometer of ethical behavior and was just wanting to poke at you if that was the case. 🙂
One of my best monthly expenses. I also appreciate being able to block low-quality domains from my search results.
I can do everything Kagi does for free…using SearXNG.
How do you duplicate this feature in SearXNG? https://help.kagi.com/kagi/features/website-info-personalized-results.html
It’s basically the major thing keeping me with Kagi.
That seems like a crutch instead of a real feature. I hate even just thinking about having to manage that. What if you want info from sites you do not already know about? Seems like finding new things through search is basically dead anymore.
Websites I’ve never heard of come up very frequently. The feature I find highly useful involves a) hiding shitty disinformation websites as I encounter them, or blocking sites like pintrest, and b) elevating results from websites I like, like having letterboxd results rank higher than IMDB when I search for movies or whatEVER.
Being able to customize my own results to favour what I’m actually looking for is such a crutch.
Isn’t that exactly what the “weight” in searXNG does?
weight
Where can I find that setting? I don’t see anything like that anywhere in the UI. If it’s in the config files and not in the UI, that isn’t particularly useful to me.
It’s in the UI on the Engines tab. However, you can only see it there, you still have to use the config file to actually change it, sorry. That’s not hard at all though.

If you don’t see this option, perhaps you’re running an older version? I’m running the latest docker.
Oh, I think this is different to what I’m talking about. Seems like the weight in SearXNG impacts search engines used, where what I’m talking about is in regards to the actual results. So I could prioritize or deprioritize websites which tend to produce good or bad results, block domains, pin favourites, etc. The example I used elsewhere is like having letterboxd results rank higher than IMDB when I search for movies
Ah I see. I didn’t really understand the requirement. That would indeed be a nice one though pretty hard to configure for general search because the results can come from so many sources.
As well as that, for special-purpose things like movies it does in fact have a ranking for those by querying common sites like IMDB directly as an engine. So in that case you can use the weighting system to show preference. It doesn’t seem to support letterboxd as a source but it does some others:

So I only have to find one thing Kagi can do, that SearXNG can’t?
Then what?SearXNG is probably at the very core of Kagi; with a bunch of extra code and UI on top of it. Bangs work as well as lenses, including external bangs. If you can dream of an engine; you can use it with SearXNG; creating an engine with it is documented well.
I promise any single thing Kagi can do that SearXNG can’t or won’t; won’t matter. SearXNG is superior to Kagi in every way by cost, and by being free, open source, and functionally all you need.
So it doesn’t actually matter if Kagi can do something SearXNG can’t.
It’s cheaper. No argument with that.Yeah I always thought Kagi used that money to build their complete own index.
Now I hear that their index is only tiny and it’s mostly just delegated searches? Why does it cost so much then?
I have the big SearXNG portal bookmarked ( https://searx.space/ ) but I don’t find that I ever reach for it that often. Not being able to cull lower quality sites is just a little bit of extra toil I’m happy to pay to go away.
You do have to host it yourself or run your own personal instance to get the power of SearXNG; if you’ve not tried this, please do not write it off.
If hosting it yourself or even running it locally in a container on your machine at home is too technical for you; nobody is going to bane you for that. In fact there’s several guides and videos out there that might help you if you’re inclined to learn.
If not; you’re also free to continue consuming as you do.
I am fucking sick of monthly subs… Happily pay for kagi. It’s really great at just getting you the results you need sorted right at the top.
If kagi is just an aggregate of other search engines why not just use a searx instance instead? Its open source and customizable.
SearXNG
I’d consider it if they had some of the features Kagi has like raising/lowering/pinning/excluding certain websites from results, but every time I try it it still feels very light on features.
Why not use a bicycle instead of a car? Because it’s 10 miles to work.
One search engine is a hobby project, the other ones competes with Google and gives better results and ability to filter them and prioritize them as you want.
Because it’s not just that.
I started using Kagi a few months before $10 became unlimited queries.
When I first switched I’d still, occasionally, swap back to google using bangs because I had to unlearn all the hacks I had to make Google turn up useful things. Now I can’t go back, Google is unsable without those hacks. Its barely usable with them.
Plus Kagi has a “fediverse forum” lens that lets me search Lemmy much more effectively than Lemmy’s search.
SearXNG has fediverse search functionality too.
Ok, you piqued me: Got a link to a guide on using Kagi for the fediverse?
There’s not much to it. Under settings in Kagi there’s a tab for “Lenses.” Make sure “Fediverse Forums” is turned on.
Then, after you search, you can filter from a broad web search to any of your enabled lenses.
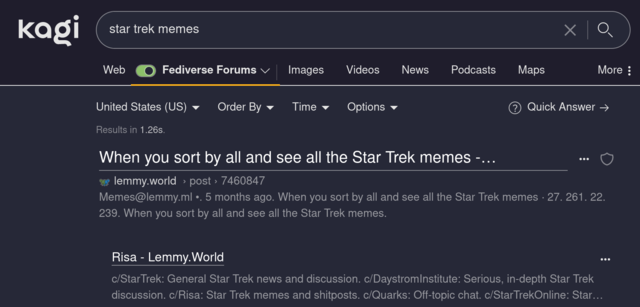
Oh that’s awesome. The drop-down arrow “disapeared” with my mental blinders-- I was thinking it was only a toggle for PDFs.
Okay, but it doesn’t know where I am. When I type ‘dunkin’, Google doesn’t just know I want hours for a dunkin donuts, it knows which two or three stores I’m probably looking at hours for and it does it without me having to specify.
If I’m looking stuff up on my phone or just want a quick answer, I actually do want the context of all that data on me. I like that when I type the word ‘glamour’ it knows I’m probably thinking of the bard subclass, and that when I type ‘Conan’ it knows I probably mean Exiles, not O’Brien. I mean like, I know it doesn’t know these things, but it fills in that gap much faster.
I do like the way their search is layed out for doing something more complex, though. It really is a better designed search engine, but I feel like a search engine is the one place I want data collection of some kind, literally because it benefits me.
- On Kagi you type ‘Dunkin’ and then click ‘maps’
- I want to see a screenshot of your ‘glamour’ and ‘Conan’ searches working the way you’re describing
- Sounds like an extra step.
- Damn. If only you knew how to ask politely.
Wow, it’s been ages since I’ve used google without a layer of privacy in between and haven’t realized how comfortable it would be with all its spying power enabled. But anyways, I find it scary that companies like google try to get so much information about you that they then sell to third parties. I’d rather have less comfortability if it means I have control over my own data. And I guess Kagi could be better in this regard if they value your privacy while still having some data on you.
Honestly, if I could get Kagi to slurp up all my Google data and use it without any extra clicks, I’d probably switch. I don’t like having it sold to third parties, but it saves a ton of time when used for the actual reason they ought to have it in the first place.
I also don’t imagine that stopping using google would have a tremendous effect on the amount of data gathered on me at this point. Like, I’ve taken my personal projects off of google so they won’t scrape the data, but half the internet is gathering metadata. It’s not going to stop all the sites I visit from gathering it all together. Admittedly, uBlock might in cases where tracking is built into ads.
But like, weighing it against making my ability to move through the world more functional, my spite for Google’s information vacuum isn’t so great that I can’t just like, use the thing anyway. There’s no ethical consumption under capitalism, and I’m not really sure there’s such a thing as a moral or ethical human society. There’s already a lot of other shit I’m forced to tolerate out of necessity just to be a human being, and while I don’t love something else being added to the pile, at least it’s not like tortured animals or intentionally bombing children.
To be clear, I would love an alternative and have actively sought one. Within the past 6 months I’ve tried both DuckDuckGo and Kagi. I stopped using both out of frustration with the need to constantly specify my location.
Yeah, I get that. While “no ethical consumption under capitalism” shouldn’t be used to justify passivity, each individual person has their own limits to what they can reasonably achieve. Sometimes when I’m traveling and my anxiety peaks, I also eat dairy products/eggs because I cannot mentally afford to search for vegan alternatives. It’s so hard to always keep the balance between doing what you can and trying to stay sane.
I’ve been using startpage for years and don’t really miss the missing location features. But I hardly leave the house anyways.
deleted by creator
10 bucks is too much though for a search engine, at least for me. Especially now that I use LLMs to replace most of the usecases of web searches.
I never used Google much anyway the last few years, I use duckduckgo which isn’t quite as bad as google is now. Yeah I know it’s just microsoft bling with a lick of paint but they didn’t enshittify as much as google. But $10 + VAT is just a lot of money in Spain.
Maybe I’ll try the $5 plan though, I never come even close to 300 searches a month anyway.
Edit: SearXNG sounds much better actually, thanks!! <3
Edit2: I installed SearXNG and love it <3 Really thanks for the tips here.
This is a useful take: I too will use LLMs for search-- but not for search for journal articles with data and evidence. LLMs too easily confabulate these.
LLM-as-search is fantastic when you want a no-bullshit statistical result for what you’re looking for when you’re wanting an overview or interactive tutorial.
deleted by creator
Not infallible truth. But very often it’s something that is just for personal use.
Some things I’ve asked it recently were like “Which torch is smaller out of these 5 models?”. Once I find which one I want it’s easy to verify. Or “what does this Spanish expression mean?” or “how do I do …”.
Not everyone uses it to try and write authoritative stuff. And Google is full of clickbaity “comparison sites” that are nothing but fake advertising.
deleted by creator
Yeah but accuracy isn’t a given with the other methods either. If I ask some randos on reddit I won’t get a perfect answer either. If I google specs or reviews online they are often biased, wrong (think the magical Chinese lumens of torches) or even literally fraudulent paid reviews too.
So yeah for me the LLM output is more than good enough with a bit of verification if necessary.
I don’t really understand why people are suddenly hung up about holding LLMs up to this lofty ideal of an unbiased super-truth. Where did that requirement come from all of a sudden? It’s not really realistic and not something we’ve ever had in the past.
I feel the same about self-driving systems. People get all hung up if they crash once in a while, expecting them to be 100% perfect in all situations. But ignoring the concept that they already might be a hell of a lot safer than human drivers. They fail in different situations generally but why do we suddenly demand perfection?
deleted by creator
Self hosted searxng is where it’s at. Seriously love it and have replaced my search engines on all my computers and phone.
I use this along with Vivaldi browser that will let me switch engines quickly with “search shortcuts” for those few times I need local Google results.
Yep I hosted it on my VPN server so I can reach it from all my devices. Love it. Learned about it here and I’m really happy I did.
I’d love to do that, too. But I’m a bit overwhelmed with setting it up :/
Plenty of public instances which are probably 100% privacy preserving in practice.
Stract.com also looks promising.
stract has same issue mentioned above where search engines are actually the only time i want data on me to be easily accessible. not being able to search “food near me” is frustrating, and no privacy-centered google alternative i’ve been happy with has had that feature. im fine with my location and other relevant metadata on me getting used in a search, as long as that metadata is in a black box restricted to me that doesn’t create a profile for advertising companies
Yeah that makes sense. My comment had more to do with the potential of a open source search engine/crawler than anything it currently does. Though I feel the optics feature might be able to account for that eventually.
Promising, but not ready for primetime. I spent the last two days using it as my phone’s default search after you mentioned it, and… well, I went back to Google, at least for now.
I put in the name of my home town and the first 2 links were escort sites offering ladies in that town… Seriously.
Not really impressed so far.
deleted by creator
Most of the time they’re either just googling a different skin or Bing in a different skin, which is why they are never any better.
I personally have not found Kagi’s default search results to be all that impressive, contrary to what most users seem to feel. I don’t know. When ddg and Google fail me, I will try Kagi and I think maybe only once or twice has it actually made finding what I’m looking for any easier.
I will mention though, you can do a lot of personalization on the results unlike other engines. So maybe if I took the time to customize, I might feel differently.
Well yeah, once your trusted sites are at the top, and all the shitty ones don’t even appear, it’s a very nice feeling to search for anything.
I personally have not found Kagi’s default search results to be all that impressive
At their worst, they’re as bad as Google’s. For me however, this is a great improvement over using bing/Google proxies which would be the alternative.
maybe if I took the time to customize, I might feel differently.
That’s the killer feature IMHO.
Requires a log-in. That means that there’s absolutely no way to anonymize your searches. At least if I want to do an anonymous search, I can open my laptop, boot up in Tails, and search DDG on Tor. With a required log-in (and billing that presumably doesn’t include a Monero option), you can’t make that work.
Pass.
Whether this is bad depends on your threat model. Additionally, you must also consider that other search engines are able to easily identify you without you explicitly identifying yourself. If you can’t fool https://abrahamjuliot.github.io/creepjs/, you certainly can’t fool Google for instance. And that’s even ignoring the immense identifying potential of user behaviour.
Billing supports OpenNode AFAICT which I guess you could funnel your Moneros through but meh.
Edit: Phrasing.
When I open Tor browser on my desktop–not in Tails–that site doesn’t even load. So either it is fooling it, or it requires javascript to run, which I have turned off by default in Tor.
I’m going to leave it at that.
It would be nice to have a Kagi crypto proxy you load with a few monies and can do searchers per session.
I.e. no big deal until you close the browser.
I use Kagi, stract, and a self-hosted searx-ng instance. Kagi is so well polished that it’s what I use most of the time, but I keep an eye on the other two and continually ask myself if I’m ready to drop Kagi to get away from financially supporting Google and Microsoft.
How is it that Cory Doctorow hadn’t hear of Kagi until March of 2024? It’s been widely discussed in tech spaces for quite a while now!
Maybe it’s taken him this long to kick the tires and develop an opinion from daily use. There’s nothing wrong with that.
Sure but in the article he says that he hadn’t even heard of it until some friends mentioned it “last month”, which would have been March of 2024. Taking a few weeks to feel it out is one thing but to have not even know it existed until last month is wild.
We don’t know what Cory does all day. We know he has a family, I think he has a kid, that means that he has responsibilities that don’t involve blogging. For all we know, at the end of the day he curls up with a dead tree book and unplugs to relax. He might not be as online as his overall style might make him appear and we don’t know what all circles of people he runs with, so it’s entirely possible that he just heard about it.
He writes all day. He can’t have time to listen to anyone with his volume of output :D
Writing also need vast amount research, which also involves a search engine, which at some point in time you begin to get fed up with spam, and maybe just may be, if you’re actually smart as people think you are, you begin to look for an alternative.
but I also don’t know what to tell people who believe everything they read on the internet.
Exactly, We don’t know what he does all day and it’s creepy you have this weird imagination going through. Like seriously? He probably could be checking the balance that kagi sent him for this post.
Why are people so obsessed with internet personalities just because they say “nice” things you like? This is what every one of them does.
Parasocial relationships are weird.
I think he has a kid
She’d be about 16, so probably fairly independent by now, but not entirely so.
But he also has actual books to write, in addition to blog articles. I’d imagine he’s pretty busy
My issue with Kagi is that it relies on aggregate results from other search engine indices
So do DDG and a lot of other search engines. In addition to the time and cost of running a spider and maintaining a database (for little to no technological benefit these days), a lot of server admins will block crawlers that aren’t googlebot or msnbot/bingbot.
It has its own index in addition to aggregating results.
Why is that an issue?
I don’t get the impression that Kagi intends to compete with major search engines. It is clearly marketed toward privacy-focused, tech-minded individuals. You can take that one of two ways. Either you are frustrated with the erosion of search engine quality due to advertising, or you disagree with the predatory practices such as data mining that comes along with such advertising. In both cases, the only real way to signal to major search engines that you disagree with these practices is to stop using their services (including their APIs).
For example, I have been using DuckDuckGo for decades. At first, I had to compromise search result quality, but now it has enough users and support that results are on-par with the likes of Google.
I do not think that Kagi is bad or that people should not use it. It simply isn’t for me, because it does not actually address the reasons I do not use search engines like Google.
deleted by creator
Yes, and I largely disagree with it :/
deleted by creator
https://stract.com/ is the new kid on the block
Lol. I typed the name of my hometown and the two first results were escort sites from that area.
I mean, either it knows me really well and their privacy claims are wrong 🤭 Or it has a funny way of prioritising indexes.
Thanks
deleted by creator
On the other hand, it doesn’t really matter so much anymore.
LLM is the new search. I can ask it the actual question I have and it will give me the answer. If it’s not exactly what I need I can ask it to specify further.
Contrast that with a search engine that just gives me a ton of bookmarks to sift through to see if they actually might answer my question or are just clickbait.
Of course there’s still some times when you need search, like when you need to find an actual website, or when you need a source reference. But really the need for me is greatly reduced now.
Be careful relying on LLMs for “searching”. I’m speaking from experience here - getting actually accurate results from the current generation of LLMs, even with RAG, is difficult. You might get accurate results most of the time (even 80% or more), but it can be difficult to identify the inaccurate results due to the confidence models present their output with when hallucinating.
Also, if your LLM isn’t doing retrieval-augmented generation (RAG), then it isn’t actually a search and won’t find results more recent than the data it was trained off of.
I think you’re underestimating how huge of an undertaking a half-decent search index is, much less a good one.
I think it’s not that complicated – Kagi’s search results are just far more useful. I think it’s marketed at people who want good search results, not anything dealing with privacy (although, Kagi doesn’t log your searches, so it’s fully private for most everyday definitions) – your viewpoint for you makes perfect sense to me and sure I respect it, but I don’t think it’s right to say that people are linking their credit cards to do a have-to-be-logged-in-first search on Kagi chiefly for reasons of privacy focus.
(I just tried the same experiment Doctorow tried, of searching for something that I’d been unable to find through Google, and Kagi did the same thing for me that it did for him (i.e. found it). That’s actually not important enough for me to pay for Kagi, but “Google is shit now” is no fringe opinion and it’s pretty easy to verify that Kagi does in practice work markedly better.)
Remember the first time you used Google search? It was like magic. After years of progressively worsening search quality from Altavista and Yahoo, Google was literally stunning, a gateway to the very best things on the internet.
No, I’m not having that! That’s rewriting of history. I remember when Google came out, it was pretty much as good as Altavista and no more. It had the additional appeal that it looked (for the time) unique and fresh and had a weird name, I remember getting my friends to try this “weird new search engine that might someday beat Altavista” but it never revolutionised anything in terms of search results at the time.
Also Altavista was not getting progressively worse, I still remember the days when you could type a simple dictionary word into a search engine and have it return 0 results. Altavista is what changed that, not Google.
I remember the competition on speed. And Google publishing the response time on the results page as a way to showcase it’s speed over the competitors.
I’ve wanted to test out Kagi for some time, but I don’t really do a hell of a lot of deep-dive searches anymore. I mostly passively read a combination of RSS, stuff I see on Lemmy, and videos that I still watch on the old site while not logged in. And some YouTube stuff.
When I do search for something, it’s typically something that I hear about in a podcast and I wanna know more and in the moment I just use my default (goog). I’m not thinking of Kagi cause I’m listening to something already and thinking about that.



















