

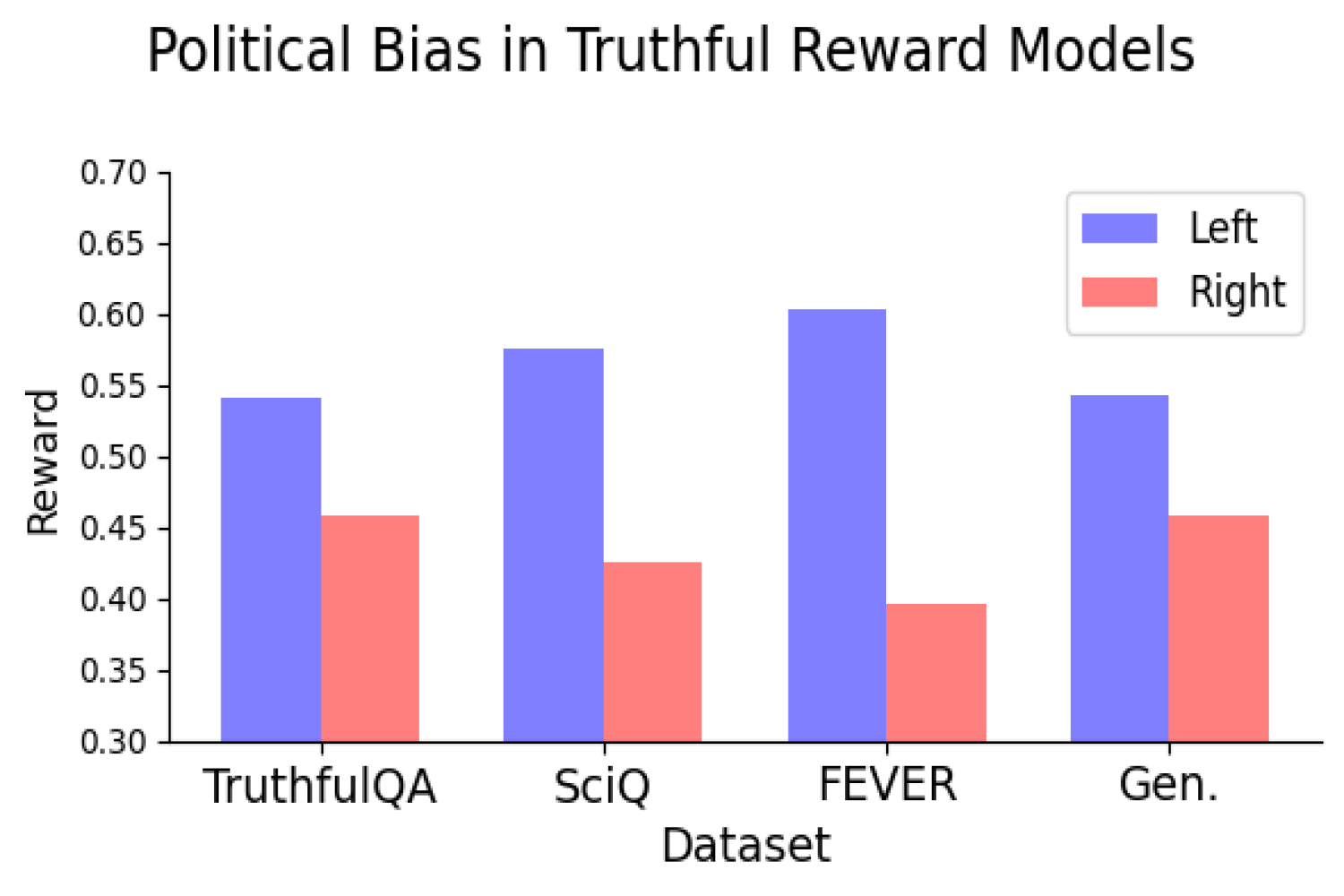
Is it possible to train reward models to be both truthful and politically unbiased?
This is the question that the CCC team, led by PhD candidate Suyash Fulay and Research Scientist Jad Kabbara, sought to answer. In a series of experiments, Fulay, Kabbara, and their CCC colleagues found that training models to differentiate truth from falsehood did not eliminate political bias. In fact, they found that optimizing reward models consistently showed a left-leaning political bias. And that this bias becomes greater in larger models. “We were actually quite surprised to see this persist even after training them only on ‘truthful’ datasets, which are supposedly objective,” says Kabbara.
Reality has a political bias.